Data Structures
Data Structures Overview

Type Aliases
| name | type |
|---|---|
Amount | uint64 |
Graffiti | byte[MAX_GRAFFITI_BYTES] |
HashDigest | byte[32] |
Height | int64 |
Nonce | uint64 |
Round | int32 |
StateSubtreeID | byte |
Timestamp | google.protobuf.Timestamp |
VotingPower | uint64 |
Blockchain Data Structures
Block
Blocks are the top-level data structure of the Celestia blockchain.
| name | type | description |
|---|---|---|
header | Header | Block header. Contains primarily identification info and commitments. |
availableDataHeader | AvailableDataHeader | Header of available data. Contains commitments to erasure-coded data. |
availableData | AvailableData | Data that is erasure-coded for availability. |
lastCommit | Commit | Previous block's Tendermint commit. |
Header
Block header, which is fully downloaded by both full clients and light clients.
| name | type | description |
|---|---|---|
version | ConsensusVersion | The consensus version struct. |
chainID | string | The CHAIN_ID. |
height | Height | Block height. The genesis block is at height 1. |
timestamp | Timestamp | Timestamp of this block. |
lastHeaderHash | HashDigest | Previous block's header hash. |
lastCommitHash | HashDigest | Previous block's Tendermint commit hash. |
consensusHash | HashDigest | Hash of consensus parameters for this block. |
AppHash | HashDigest | The state root after the previous block's transactions are applied. |
availableDataOriginalSharesUsed | uint64 | The number of shares used in the original data square that are not tail padding. |
availableDataRoot | HashDigest | Root of commitments to erasure-coded data. |
proposerAddress | Address | Address of this block's proposer. |
The size of the original data square, availableDataOriginalSquareSize, isn't explicitly declared in the block header. Instead, it is implicitly computed as the smallest power of 2 whose square is at least availableDataOriginalSharesUsed (in other words, the smallest power of 4 that is at least availableDataOriginalSharesUsed).
The header hash is the hash of the serialized header.
AvailableDataHeader
| name | type | description |
|---|---|---|
rowRoots | HashDigest[] | Commitments to all erasure-coded data. |
colRoots | HashDigest[] | Commitments to all erasure-coded data. |
The number of row/column roots of the original data shares in square layout for this block. The availableDataRoot of the header is computed using the compact row and column roots as described in the 2D Reed-Solomon encoding scheme.
The number of row and column roots is each availableDataOriginalSquareSize * 2, and must be a power of 2. Note that the minimum availableDataOriginalSquareSize is 1 (not 0), therefore the number of row and column roots are each at least 2.
Implementations can prune rows containing only tail padding as they are implicitly available.
AvailableData
Data that is erasure-coded for data availability checks.
| name | type | description |
|---|---|---|
transactions | Transaction | Transactions are ordinary Cosmos SDK transactions. For example: they may modify the validator set and token balances. |
payForBlobData | PayForBlobData | PayForBlob data. Transactions that pay for blobs to be included. |
blobData | BlobData | Blob data is arbitrary user submitted data that will be published to the Celestia blockchain. |
Commit
| name | type | description |
|---|---|---|
height | Height | Block height. |
round | Round | Round. Incremented on view change. |
headerHash | HashDigest | Header hash of the previous block. |
signatures | CommitSig[] | List of signatures. |
Timestamp
Timestamp is a type alias.
Celestia uses google.protobuf.Timestamp to represent time.
HashDigest
HashDigest is a type alias.
Output of the hashing function. Exactly 256 bits (32 bytes) long.
TransactionFee
| name | type | description |
|---|---|---|
tipRate | uint64 | The tip rate for this transaction. |
Abstraction over transaction fees.
Address
Celestia supports secp256k1 keys where addresses are 20 bytes in length.
| name | type | description |
|---|---|---|
AccAddress | [20]byte | AccAddress a wrapper around bytes meant to represent an account address |
CommitSig
enum CommitFlag : uint8_t {
CommitFlagAbsent = 1,
CommitFlagCommit = 2,
CommitFlagNil = 3,
};
| name | type | description |
|---|---|---|
commitFlag | CommitFlag | |
validatorAddress | Address | |
timestamp | Timestamp | |
signature | Signature |
Signature
| name | type | description |
|---|---|---|
r | byte[32] | r value of the signature. |
s | byte[32] | s value of signature. |
ConsensusVersion
| name | type | description |
|---|---|---|
block | uint64 | The VERSION_BLOCK. |
app | uint64 | The app version. |
Serialization
Objects that are committed to or signed over require a canonical serialization. This is done using a deterministic (and thus, bijective) variant of protobuf defined in ADR-027.
Note: there are two requirements for a serialization scheme, should this need to be changed:
- Must be bijective.
- Serialization must include the length of dynamic structures (e.g. arrays with variable length).
Hashing
All protocol-level hashing is done using SHA-2-256 as defined in FIPS 180-4. SHA-2-256 outputs a digest that is 256 bits (i.e. 32 bytes) long.
Libraries implementing SHA-2-256 are available in Go (https://pkg.go.dev/crypto/sha256) and Rust (https://docs.rs/sha2/latest/sha2/).
Unless otherwise indicated explicitly, objects are first serialized before being hashed.
Merkle Trees
Merkle trees are used to authenticate various pieces of data across the Celestia stack, including transactions, blobs, the validator set, etc. This section provides an overview of the different tree types used, and specifies how to construct them.
Binary Merkle Tree
Binary Merkle trees are constructed in the same fashion as described in Certificate Transparency (RFC-6962), except for using a different hashing function. Leaves are hashed once to get leaf node values and internal node values are the hash of the concatenation of their children (either leaf nodes or other internal nodes).
Nodes contain a single field:
| name | type | description |
|---|---|---|
v | HashDigest | Node value. |
The base case (an empty tree) is defined as the hash of the empty string:
node.v = 0xe3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
For leaf node node of leaf data d:
node.v = h(0x00, serialize(d))
For internal node node with children l and r:
node.v = h(0x01, l.v, r.v)
Note that rather than duplicating the last node if there are an odd number of nodes (the Bitcoin design), trees are allowed to be imbalanced. In other words, the height of each leaf may be different. For an example, see Section 2.1.3 of Certificate Transparency (RFC-6962).
Leaves and internal nodes are hashed differently: the one-byte 0x00 is prepended for leaf nodes while 0x01 is prepended for internal nodes. This avoids a second-preimage attack where internal nodes are presented as leaves trees with leaves at different heights.
BinaryMerkleTreeInclusionProof
| name | type | description |
|---|---|---|
siblings | HashDigest[] | Sibling hash values, ordered starting from the leaf's neighbor. |
A proof for a leaf in a binary Merkle tree, as per Section 2.1.1 of Certificate Transparency (RFC-6962).
Namespace Merkle Tree
Shares in Celestia are associated with a provided namespace. The Namespace Merkle Tree (NMT) is a variation of the Merkle Interval Tree, which is itself an extension of the Merkle Sum Tree. It allows for compact proofs around the inclusion or exclusion of shares with particular namespace IDs.
Nodes contain three fields:
| name | type | description |
|---|---|---|
n_min | Namespace | Min namespace in subtree rooted at this node. |
n_max | Namespace | Max namespace in subtree rooted at this node. |
v | HashDigest | Node value. |
The base case (an empty tree) is defined as:
node.n_min = 0x0000000000000000
node.n_max = 0x0000000000000000
node.v = 0xe3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
For leaf node node of share data d:
node.n_min = d.namespace
node.n_max = d.namespace
node.v = h(0x00, d.namespace, d.rawData)
The namespace blob field here is the namespace of the leaf, which is a NAMESPACE_SIZE-long byte array.
Leaves in an NMT must be lexicographically sorted by namespace in ascending order.
For internal node node with children l and r:
node.n_min = min(l.n_min, r.n_min)
if l.n_min == PARITY_SHARE_NAMESPACE
node.n_max = PARITY_SHARE_NAMESPACE
else if r.n_min == PARITY_SHARE_NAMESPACE
node.n_max = l.n_max
else
node.n_max = max(l.n_max, r.n_max)
node.v = h(0x01, l.n_min, l.n_max, l.v, r.n_min, r.n_max, r.v)
Note that the above snippet leverages the property that leaves are sorted by namespace: if l.n_min is PARITY_SHARE_NAMESPACE, so must {l,r}.n_max. By construction, either both the min and max namespace of a node will be PARITY_SHARE_NAMESPACE, or neither will: if r.n_min is PARITY_SHARE_NAMESPACE, so must r.n_max.
For some intuition: the min and max namespace for subtree roots with at least one non-parity leaf (which includes the root of an NMT, as the right half of an NMT as used in Celestia will be parity shares) ignore the namespace ID for the parity leaves. Subtree roots with only parity leaves have their min and max namespace ID set to PARITY_SHARE_NAMESPACE. This allows for shorter proofs into the tree than if the namespace ID of parity shares was not ignored (which would cause the max namespace ID of the root to always be PARITY_SHARE_NAMESPACE).
A compact commitment can be computed by taking the hash of the serialized root node.
NamespaceMerkleTreeInclusionProof
| name | type | description |
|---|---|---|
siblingValues | HashDigest[] | Sibling hash values, ordered starting from the leaf's neighbor. |
siblingMins | Namespace[] | Sibling min namespace IDs. |
siblingMaxes | Namespace[] | Sibling max namespace IDs. |
When verifying an NMT proof, the root hash is checked by reconstructing the root node root_node with the computed root_node.v (computed as with a plain Merkle proof) and the provided rootNamespaceMin and rootNamespaceMax as the root_node.n_min and root_node.n_max, respectively.
Erasure Coding
In order to enable trust-minimized light clients (i.e. light clients that do not rely on an honest majority of validating state assumption), it is critical that light clients can determine whether the data in each block is available or not, without downloading the whole block itself. The technique used here was formally described in the paper Fraud and Data Availability Proofs: Maximising Light Client Security and Scaling Blockchains with Dishonest Majorities.
The remainder of the subsections below specify the 2D Reed-Solomon erasure coding scheme used, along with the format of shares and how available data is arranged into shares.
Reed-Solomon Erasure Coding
Note that while data is laid out in a two-dimensional square, rows and columns are erasure coded using a standard one-dimensional encoding.
Reed-Solomon erasure coding is used as the underlying coding scheme. The parameters are:
- 16-bit Galois field
availableDataOriginalSquareSizeoriginal pieces (maximum ofAVAILABLE_DATA_ORIGINAL_SQUARE_MAX)availableDataOriginalSquareSizeparity pieces (maximum ofAVAILABLE_DATA_ORIGINAL_SQUARE_MAX) (i.eavailableDataOriginalSquareSize * 2total pieces), for an erasure efficiency of 50%. In other words, any 50% of the pieces from theavailableDataOriginalSquareSize * 2total pieces are enough to recover the original data.SHARE_SIZEbytes per piece
Note that availableDataOriginalSquareSize may vary each block, and is decided by the block proposer of that block. Leopard-RS is a C library that implements the above scheme with quasilinear runtime.
2D Reed-Solomon Encoding Scheme
The 2-dimensional data layout is described in this section. The roots of NMTs for each row and column across four quadrants of data in a 2k * 2k matrix of shares, Q0 to Q3 (shown below), must be computed. In other words, 2k row roots and 2k column roots must be computed. The row and column roots are stored in the availableDataCommitments of the AvailableDataHeader.

The data of Q0 is the original data, and the remaining quadrants are parity data. Setting k = availableDataOriginalSquareSize, the original data first must be split into shares and arranged into a k * k matrix. Then the parity data can be computed.
Where A -> B indicates that B is computed using erasure coding from A:
Q0 -> Q1for each row inQ0andQ1Q0 -> Q2for each column inQ0andQ2Q2 -> Q3for each row inQ2andQ3
Note that the parity data in Q3 will be identical if it is vertically extended from Q1 or horizontally extended from Q2.

As an example, the parity data in the second column of Q2 (in striped purple) is computed by extending the original data in the second column of Q0 (in solid blue).

Now that all four quadrants of the 2k * 2k matrix are filled, the row and column roots can be computed. To do so, each row/column is used as the leaves of a NMT, for which the compact root is computed (i.e. an extra hash operation over the NMT root is used to produce a single HashDigest). In this example, the fourth row root value is computed as the NMT root of the fourth row of Q0 and the fourth row of Q1 as leaves.

Finally, the availableDataRoot of the block Header is computed as the Merkle root of the binary Merkle tree with the row and column roots as leaves, in that order.

Arranging Available Data Into Shares
The previous sections described how some original data, arranged into a k * k matrix, can be extended into a 2k * 2k matrix and committed to with NMT roots. This section specifies how available data (which includes transactions, PayForBlob transactions, and blobs) is arranged into the matrix in the first place.
Note that each share only has a single namespace, and that the list of concatenated shares is lexicographically ordered by namespace.
Then,
- For each of
transactionData,intermediateStateRootData, PayForBlob transactions, serialize:- For each request in the list:
- Serialize the request (individually).
- Compute the length of each serialized request, serialize the length, and prepend the serialized request with its serialized length.
- Split up the length/request pairs into
SHARE_SIZE-NAMESPACE_ID_SIZE-SHARE_RESERVED_BYTES-byte chunks. - Create a share out of each chunk. This data has a reserved namespace ID, so the first
NAMESPACE_SIZE+SHARE_RESERVED_BYTESbytes for these shares must be set specially.
- For each request in the list:
- Concatenate the lists of shares in the order: transactions, intermediate state roots, PayForBlob transactions.
These shares are arranged in the first quadrant (Q0) of the availableDataOriginalSquareSize*2 * availableDataOriginalSquareSize*2 available data matrix in row-major order. In the example below, each reserved data element takes up exactly one share.

Each blob in the list blobData:
- Serialize the blob (individually).
- Compute the length of each serialized blob, serialize the length, and prepend the serialized blob with its serialized length.
- Split up the length/blob pairs into
SHARE_SIZE-NAMESPACE_SIZE-byte chunks. - Create a share out of each chunk. The first
NAMESPACE_SIZEbytes for these shares is set to the namespace.
For each blob, it is placed in the available data matrix, with row-major order, as follows:
- Place the first share of the blob at the next unused location in the matrix, then place the remaining shares in the following locations.
Transactions must commit to a Merkle root of a list of hashes that are each guaranteed (assuming the block is valid) to be subtree roots in one or more of the row NMTs. For additional info, see the rationale document for this section.
However, with only the rule above, interaction between the block producer and transaction sender may be required to compute a commitment to the blob the transaction sender can sign over. To remove interaction, blobs can optionally be laid out using a non-interactive default:
- Place the first share of the blob at the next unused location in the matrix whose column is aligned with the largest power of 2 that is not larger than the blob length or
availableDataOriginalSquareSize, then place the remaining shares in the following locations unless there are insufficient unused locations in the row. - If there are insufficient unused locations in the row, place the first share of the blob at the first column of the next row. Then place the remaining shares in the following locations. By construction, any blob whose length is greater than
availableDataOriginalSquareSizewill be placed in this way.
In the example below, two blobs (of lengths 2 and 1, respectively) are placed using the aforementioned default non-interactive rules.

The blob share commitment rules may introduce empty shares that do not belong to any blob (in the example above, the top-right share is empty). These are zeroes with namespace ID equal to the either TAIL_TRANSACTION_PADDING_NAMESPACE_ID if between a request with a reserved namespace ID and a blob, or the namespace ID of the previous blob if succeeded by a blob. See the data square layout for more info.
Available Data
Transaction
Celestia transactions are Cosmos SDK transactions.
PayForBlobData
IndexWrapper
IndexWrapper are wrappers around PayForBlob transactions. They include additional metadata by the block proposer that is committed to in the available data matrix.
| name | type | description |
|---|---|---|
tx | bytes | Actual transaction. |
share_indexes | []uint32 | Share indexes (in row-major order) of the first share for each blob this transaction pays for. Needed for light verification of proper blob inclusion. |
type_id | string | Type ID of the IndexWrapper transaction type. This is used for encoding and decoding IndexWrapper transactions. It is always set to "INDX". |
BlobData
| name | type | description |
|---|---|---|
blobs | Blob[] | List of blobs. |
Blob
| name | type | description |
|---|---|---|
namespaceID | NamespaceID | Namespace ID of this blob. |
rawData | byte[] | Raw blob bytes. |
State
The state of the Celestia chain is intentionally restricted to containing only account balances and the validator set metadata. Similar to other Cosmos SDK based chains, the state of the Celestia chain is maintained in a multistore. The root of the application state is committed to in the block header via the AppHash.
Consensus Parameters
Various consensus parameters are committed to in the block header, such as limits and constants.
| name | type | description |
|---|---|---|
version | ConsensusVersion | The consensus version struct. |
chainID | string | The CHAIN_ID. |
shareSize | uint64 | The SHARE_SIZE. |
shareReservedBytes | uint64 | The SHARE_RESERVED_BYTES. |
availableDataOriginalSquareMax | uint64 | The AVAILABLE_DATA_ORIGINAL_SQUARE_MAX. |
In order to compute the consensusHash field in the block header, the above list of parameters is hashed.
Namespace
Abstract
One of Celestia's core data structures is the namespace.
When a user submits a transaction encapsulating a MsgPayForBlobs message to Celestia, they MUST associate each blob with exactly one namespace.
After their transaction has been included in a block, the namespace enables users to take an interest in a subset of the blobs published to Celestia by allowing the user to query for blobs by namespace.
In order to enable efficient retrieval of blobs by namespace, Celestia makes use of a Namespaced Merkle Tree. See section 5.2 of the LazyLedger whitepaper for more details.
Overview
A namespace is composed of two fields: version and id. A namespace is encoded as a byte slice with the version and id concatenated.

Version
The namespace version is an 8-bit unsigned integer that indicates the version of the namespace. The version is used to determine the format of the namespace and is encoded as a single byte. A new namespace version MUST be introduced if the namespace format changes in a backwards incompatible way.
Below we explain supported user-specifiable namespace versions, however, we note that Celestia MAY utilize other namespace versions for internal use. For more details, see the Reserved Namespaces section.
Version 0
The only supported user-specifiable namespace version is 0.
A namespace with version 0 MUST contain an id with a prefix of 18 leading 0 bytes.
The remaining 10 bytes of the id are user-specified.
Below, we provide examples of valid and invalid encoded user-supplied namespaces with version 0.
// Valid encoded namespaces
0x0000000000000000000000000000000000000001010101010101010101 // valid blob namespace
0x0000000000000000000000000000000000000011111111111111111111 // valid blob namespace
// Invalid encoded namespaces
0x0000000000000000000000000111111111111111111111111111111111 // invalid because it does not have 18 leading 0 bytes
0x1000000000000000000000000000000000000000000000000000000000 // invalid because it does not have version 0
0x1111111111111111111111111111111111111111111111111111111111 // invalid because it does not have version 0
Any change in the number of leading 0 bytes in the id of a namespace with version 0 is considered a backwards incompatible change and MUST be introduced as a new namespace version.
ID
The namespace ID is a 28 byte identifier that uniquely identifies a namespace. The ID is encoded as a byte slice of length 28.
Reserved Namespaces
Celestia reserves some namespaces for protocol use. These namespaces are called "reserved namespaces". Reserved namespaces are used to arrange the contents of the data square. Applications MUST NOT use reserved namespaces for their blob data. Reserved namespaces fall into two categories: Primary and Secondary.
- Primary: Namespaces with values less than or equal to
0x00000000000000000000000000000000000000000000000000000000FF. Primary namespaces always have a version of0. - Secondary: Namespaces with values greater than or equal to
0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00. Secondary namespaces always have a version of255(0xFF) so that they are placed after all user specifiable namespaces in a sorted data square. ThePARITY_SHARE_NAMESPACEuses version255(0xFF) to enable more efficient proof generation within the context of nmt, where it is used in conjunction with theIgnoreMaxNamespacefeature. TheTAIL_PADDING_NAMESPACEuses the version255to ensure that padding shares are always placed at the end of the Celestia data square even if a new user-specifiable version is introduced.
Below is a list of the current reserved namespaces. For additional information on the significance and application of the reserved namespaces, please refer to the Data Square Layout specifications.
| name | type | category | value | description |
|---|---|---|---|---|
TRANSACTION_NAMESPACE | Namespace | Primary | 0x0000000000000000000000000000000000000000000000000000000001 | Namespace for ordinary Cosmos SDK transactions. |
INTERMEDIATE_STATE_ROOT_NAMESPACE | Namespace | Primary | 0x0000000000000000000000000000000000000000000000000000000002 | Namespace for intermediate state roots (not currently utilized). |
PAY_FOR_BLOB_NAMESPACE | Namespace | Primary | 0x0000000000000000000000000000000000000000000000000000000004 | Namespace for transactions that contain a PayForBlob. |
PRIMARY_RESERVED_PADDING_NAMESPACE | Namespace | Primary | 0x00000000000000000000000000000000000000000000000000000000FF | Namespace for padding after all primary reserved namespaces. |
MAX_PRIMARY_RESERVED_NAMESPACE | Namespace | Primary | 0x00000000000000000000000000000000000000000000000000000000FF | Namespace for the highest primary reserved namespace. |
MIN_SECONDARY_RESERVED_NAMESPACE | Namespace | Secondary | 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00 | Namespace for the lowest secondary reserved namespace. |
TAIL_PADDING_NAMESPACE | Namespace | Secondary | 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFE | Namespace for padding after all blobs to fill up the original data square. |
PARITY_SHARE_NAMESPACE | Namespace | Secondary | 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF | Namespace for parity shares. |
Assumptions and Considerations
Applications MUST refrain from using the reserved namespaces for their blob data.
Celestia does not ensure the prevention of non-reserved namespace collisions. Consequently, two distinct applications might use the same namespace. It is the responsibility of these applications to be cautious and manage the implications and consequences arising from such namespace collisions. Among the potential consequences is the Woods Attack, as elaborated in this forum post: Woods Attack on Celestia.
Implementation
See the namespace implementation in go-square. For the most recent version, which may not reflect the current specifications, refer to the latest namespace code.
Go Definition
type Namespace struct {
Version uint8
ID []byte
}
References
Shares
Abstract
All available data in a Celestia block is split into fixed-size data chunks known as "shares". Shares are the atomic unit of the Celestia data square. The shares in a Celestia block are eventually erasure-coded and committed to in Namespace Merkle trees (also see NMT spec).
Terms
- Blob: User specified data (e.g. a roll-up block) that is associated with exactly one namespace. Blob data are opaque bytes of data that are included in the block but do not impact Celestia's state.
- Share: A fixed-size data chunk that is associated with exactly one namespace.
- Share sequence: A share sequence is a contiguous set of shares that contain semantically relevant data. A share sequence MUST contain one or more shares. When a blob is split into shares, it is written to one share sequence. As a result, all shares in a share sequence are typically parsed together because the original blob data may have been split across share boundaries. All transactions in the
TRANSACTION_NAMESPACEare contained in one share sequence. All transactions in thePAY_FOR_BLOB_NAMESPACEare contained in one share sequence.
Overview
User submitted transactions are split into shares (see share splitting) and arranged in a k * k matrix (see arranging available data into shares) prior to the erasure coding step. Shares in the k * k matrix are ordered by namespace and have a common share format.
Padding shares are added to the k * k matrix to ensure:
- Blob sequences start on an index that conforms to blob share commitment rules (see namespace padding share and reserved padding share)
- The number of shares in the matrix is a perfect square (see tail padding share)
Share Format
Share Version
The share version is a 7-bit big-endian unsigned integer that is used to indicate the version of the share format. A new share version MUST be introduced if the share format changes in a way that is not backwards compatible. There are two share versions share version 0 and share version 1.
Share Version 0
Every share has a fixed size SHARE_SIZE. The share format below is consistent for all shares:
- The first
NAMESPACE_VERSION_SIZEbytes of a share's raw data is the namespace version of that share (denoted by "namespace version" in the figure below). - The next
NAMESPACE_ID_SIZEbytes of a share's raw data is the namespace ID of that share (denoted by "namespace id" in the figure below). - The next
SHARE_INFO_BYTESbytes are for share information (denoted by "info byte" in the figure below) with the following structure:- The first 7 bits represent the share version in big endian form (initially, this will be
0000000for version0); - The last bit is a sequence start indicator. The indicator is
1if this share is the first share in a sequence or0if this share is a continuation share in a sequence.
- The first 7 bits represent the share version in big endian form (initially, this will be
- If this share is the first share in a sequence, it will include the length of the sequence in bytes. The next
SEQUENCE_BYTESrepresent a big-endian uint32 value (denoted by "sequence length" in the figure below). This length is placed immediately after theSHARE_INFO_BYTESfield. It's important to note that shares that are not the first share in a sequence do not contain this field. - The remaining
SHARE_SIZE-NAMESPACE_SIZE-SHARE_INFO_BYTES-SEQUENCE_BYTESbytes (if first share) orSHARE_SIZE-NAMESPACE_SIZE-SHARE_INFO_BYTESbytes (if continuation share) are raw data (denoted by "blob1" in the figure below). Typically raw data is the blob payload that user's submit in a BlobTx. However, raw data can also be transaction data (see transaction shares below). - If there is insufficient raw data to fill the share, the remaining bytes are filled with
0.
First share in a sequence:

Continuation share in a sequence:

Since raw data that exceeds SHARE_SIZE-NAMESPACE_SIZE-SHARE_INFO_BYTES - SEQUENCE_BYTES bytes will span more than one share, developers MAY choose to encode additional metadata in their raw blob data prior to inclusion in a Celestia block. For example, Celestia transaction shares encode additional metadata in the form of "reserved bytes".
Share Version 1
Share version 1 is similar to share version 0 with the addition of a signer field. The signer is located after the sequence length in the first share. The signer is SIGNER_SIZE bytes.
First share in a sequence with signer:

Continuation share in a sequence:
Transaction Shares
Transaction shares use share version 0. In order for clients to parse shares in the middle of a sequence without downloading antecedent shares, Celestia encodes additional metadata in the shares associated with reserved namespaces. At the time of writing this only applies to the TRANSACTION_NAMESPACE and PAY_FOR_BLOB_NAMESPACE. This share structure is often referred to as "compact shares" to differentiate from the share structure defined above for all shares. It conforms to the common share format with one additional field, the "reserved bytes" field, which is described below:
- Every transaction share includes
SHARE_RESERVED_BYTESbytes that contain the index of the starting byte of the length of the canonically serialized first transaction that starts in the share, or0if there is none, as a binary big endianuint32. Denoted by "reserved bytes" in the figure below. TheSHARE_RESERVED_BYTESare placed immediately after theSEQUENCE_BYTESif this is the first share in a sequence or immediately after theSHARE_INFO_BYTESif this is a continuation share in a sequence. - The remaining
SHARE_SIZE-NAMESPACE_SIZE-SHARE_INFO_BYTES-SEQUENCE_BYTES-SHARE_RESERVED_BYTESbytes (if first share) orSHARE_SIZE-NAMESPACE_SIZE-SHARE_INFO_BYTES-SHARE_RESERVED_BYTESbytes (if continuation share) are transaction or PayForBlob transaction data (denoted by "tx1" and "tx2" in the figure below). Each transaction or PayForBlob transaction is prefixed with a varint of the length of that unit (denoted by "len(tx1)" and "len(tx2)" in the figure below). - If there is insufficient transaction or PayForBlob transaction data to fill the share, the remaining bytes are filled with
0.
First share in a sequence:

where reserved bytes would be 38 as a binary big endian uint32 ([0b00000000, 0b00000000, 0b00000000, 0b00100110]).
Continuation share in a sequence:

where reserved bytes would be 80 as a binary big endian uint32 ([0b00000000, 0b00000000, 0b00000000, 0b01010000]).
Padding
Padding shares use share version 0 and conform to the share format described above. There are multiple variants of padding shares that differ based on their namespace.
- The first
NAMESPACE_VERSION_SIZEbytes of a share's raw data is the namespace version of that share (initially, this will be0). - The next
NAMESPACE_ID_SIZEbytes of a share's raw data is the namespace ID of that share. This varies based on the type of padding share. - The next
SHARE_INFO_BYTESbytes are for share information.- The first 7 bits represent the share version in big endian form (initially, this will be
0000000for version0); - The last bit is a sequence start indicator. The indicator is always
1.
- The first 7 bits represent the share version in big endian form (initially, this will be
- The next
SEQUENCE_BYTEScontain a big endianuint32of value0. - The remaining
SHARE_SIZE-NAMESPACE_SIZE-SHARE_INFO_BYTES-SEQUENCE_BYTESbytes are filled with0.
Namespace Padding Share
A namespace padding share uses the namespace of the blob that precedes it in the data square so that the data square can retain the property that all shares are ordered by namespace. A namespace padding share acts as padding between blobs so that the subsequent blob begins at an index that conforms to the blob share commitment rules. Clients MAY ignore the contents of these shares because they don't contain any significant data.
Primary Reserved Padding Share
Primary reserved padding shares use the PRIMARY_RESERVED_PADDING_NAMESPACE. Primary reserved padding shares are placed after shares in the primary reserved namespace range so that the first blob can start at an index that conforms to blob share commitment rules. Clients MAY ignore the contents of these shares because they don't contain any significant data.
Tail Padding Share
Tail padding shares use the TAIL_PADDING_NAMESPACE. Tail padding shares are placed after the last blob in the data square so that the number of shares in the data square is a perfect square. Clients MAY ignore the contents of these shares because they don't contain any significant data.
Parity Share
Parity shares are the output of the erasure coding step of the data square construction process. They occupy quadrants Q1, Q2, and Q3 of the extended data square and are used to reconstruct the original data square (Q0). Parity shares do not conform to the share format described above. In the square layout, parity shares do not have a significant namespace. When parity shares are used in NMTs, they are prefixed with the PARITY_SHARE_NAMESPACE to preserve the property that all shares are ordered by namespace.
Share Splitting
Share splitting is the process of converting a blob into a share sequence. The process is as follows:
- Create a new share and populate the prefix of the share with the blob's namespace and share version. Set the sequence start indicator to
1. Write the blob length as the sequence length. Write the blob's data into the share until the share is full. - If there is more data to write, create a new share (a.k.a continuation share) and populate the prefix of the share with the blob's namespace and share version. Set the sequence start indicator to
0. Write the remaining blob data into the share until the share is full. - Repeat the previous step until all blob data has been written.
- If the last share is not full, fill the remainder of the share with
0.
Assumptions and Considerations
- Shares are assumed to be byte slices of length 512. Parsing shares of a different length WILL result in an error.
Implementation
See go-square/shares.
References
Consensus Rules
System Parameters
Units
| name | SI | value | description |
|---|---|---|---|
1u | 1u | 10**0 | 1 unit. |
2u | k1u | 10**3 | 1000 units. |
3u | M1u | 10**6 | 1000000 units. |
4u | G1u | 10**9 | 1000000000 units. |
Constants
| name | type | value | unit | description |
|---|---|---|---|---|
AVAILABLE_DATA_ORIGINAL_SQUARE_MAX | uint64 | share | Maximum number of rows/columns of the original data shares in square layout. | |
AVAILABLE_DATA_ORIGINAL_SQUARE_TARGET | uint64 | share | Target number of rows/columns of the original data shares in square layout. | |
BLOCK_TIME | uint64 | second | Block time, in seconds. | |
CHAIN_ID | string | "Celestia" | Chain ID. Each chain assigns itself a (unique) ID. | |
GENESIS_COIN_COUNT | uint64 | 10**8 | 4u | (= 100000000) Number of coins at genesis. |
MAX_GRAFFITI_BYTES | uint64 | 32 | byte | Maximum size of transaction graffiti, in bytes. |
MAX_VALIDATORS | uint16 | 64 | Maximum number of active validators. | |
NAMESPACE_VERSION_SIZE | int | 1 | byte | Size of namespace version in bytes. |
NAMESPACE_ID_SIZE | int | 28 | byte | Size of namespace ID in bytes. |
NAMESPACE_SIZE | int | 29 | byte | Size of namespace in bytes. |
NAMESPACE_ID_MAX_RESERVED | uint64 | 255 | Value of maximum reserved namespace (inclusive). 1 byte worth of IDs. | |
SEQUENCE_BYTES | uint64 | 4 | byte | The number of bytes used to store the sequence length in the first share of a sequence |
SHARE_INFO_BYTES | uint64 | 1 | byte | The number of bytes used for share information |
SHARE_RESERVED_BYTES | uint64 | 4 | byte | The number of bytes used to store the index of the first transaction in a transaction share. Must be able to represent any integer up to and including SHARE_SIZE - 1. |
SHARE_SIZE | uint64 | 512 | byte | Size of transaction and blob shares, in bytes. |
SignerSize | int | 20 | byte | The number of bytes used to store the signer in a share. |
STATE_SUBTREE_RESERVED_BYTES | uint64 | 1 | byte | Number of bytes reserved to identify state subtrees. |
UNBONDING_DURATION | uint32 | block | Duration, in blocks, for unbonding a validator or delegation. | |
v1.Version | uint64 | 1 | First version of the application. Breaking changes (hard forks) must update this parameter. | |
v2.Version | uint64 | 2 | Second version of the application. Breaking changes (hard forks) must update this parameter. | |
VERSION_BLOCK | uint64 | 1 | Version of the Celestia chain. Breaking changes (hard forks) must update this parameter. |
Rewards and Penalties
| name | type | value | unit | description |
|---|---|---|---|---|
SECONDS_PER_YEAR | uint64 | 31536000 | second | Seconds per year. Omit leap seconds. |
TARGET_ANNUAL_ISSUANCE | uint64 | 2 * 10**6 | 4u | (= 2000000) Target number of coins to issue per year. |
Leader Selection
Refer to the CometBFT specifications for proposer selection procedure.
Fork Choice
The Tendermint consensus protocol is fork-free by construction under an honest majority of stake assumption.
If a block has a valid commit, it is part of the canonical chain. If equivocation evidence is detected for more than 1/3 of voting power, the node must halt. See proof of fork accountability.
Block Validity
The validity of a newly-seen block, block, is determined by two components, detailed in subsequent sections:
- Block structure: whether the block header is valid, and data in a block is arranged into a valid and matching data root (i.e. syntax).
- State transition: whether the application of transactions in the block produces a matching and valid state root (i.e. semantics).
Pseudocode in this section is not in any specific language and should be interpreted as being in a neutral and sane language.
Block Structure
Before executing state transitions, the structure of the block must be verified.
The following block fields are acquired from the network and parsed (i.e. deserialized). If they cannot be parsed, the block is ignored but is not explicitly considered invalid by consensus rules. Further implications of ignoring a block are found in the networking spec.
If the above fields are parsed successfully, the available data block.availableData is acquired in erasure-coded form as a list of share rows, then parsed. If it cannot be parsed, the block is ignored but not explicitly invalid, as above.
block.header
The block header block.header (header for short) is the first thing that is downloaded from the new block, and commits to everything inside the block in some way. For previous block prev (if prev is not known, then the block is ignored), and previous block header prev.header, the following checks must be true:
availableDataOriginalSquareSize is computed as described in the header section.
header.height==prev.header.height + 1.header.timestamp>prev.header.timestamp.header.lastHeaderHash== the header hash ofprev.header.lastCommitHash== the hash oflastCommit.header.consensusHash== the value computed using consensus parameters.header.stateCommitment== the root of the state, computed with the application of all state transitions in this block.availableDataOriginalSquareSize<=AVAILABLE_DATA_ORIGINAL_SQUARE_MAX.header.availableDataRoot== the Merkle root of the tree with the row and column roots ofblock.availableDataHeaderas leaves.header.proposerAddress== the leader forheader.height.
block.availableDataHeader
The available data header block.availableDataHeader (availableDataHeader for short) is then processed. This commits to the available data, which is only downloaded after the consensus commit is processed. The following checks must be true:
- Length of
availableDataHeader.rowRoots==availableDataOriginalSquareSize * 2. - Length of
availableDataHeader.colRoots==availableDataOriginalSquareSize * 2. - The length of each element in
availableDataHeader.rowRootsandavailableDataHeader.colRootsmust be32.
block.lastCommit
The last commit block.lastCommit (lastCommit for short) is processed next. This is the Tendermint commit (i.e. polka of votes) for the previous block. For previous block prev and previous block header prev.header, the following checks must be true:
lastCommit.height==prev.header.height.lastCommit.round>=1.lastCommit.headerHash== the header hash ofprev.- Length of
lastCommit.signatures<=MAX_VALIDATORS. - Each of
lastCommit.signaturesmust be a valid CommitSig - The sum of the votes for
previnlastCommitmust be at least 2/3 (rounded up) of the voting power ofprev's next validator set.
block.availableData
The block's available data (analogous to transactions in contemporary blockchain designs) block.availableData (availableData for short) is finally processed. The list of share rows is parsed into the actual data structures using the reverse of the process to encode available data into shares; if parsing fails here, the block is invalid.
Once parsed, the following checks must be true:
- The commitments of the erasure-coded extended
availableDatamust match those inheader.availableDataHeader. Implicitly, this means that both rows and columns must be ordered lexicographically by namespace since they are committed to in a Namespace Merkle Tree. - Length of
availableData.intermediateStateRootData== length ofavailableData.transactionData+ length ofavailableData.payForBlobData+ 2. (Two additional state transitions are the begin and end block implicit transitions.)
State Transitions
Once the basic structure of the block has been validated, state transitions must be applied to compute the new state and state root.
For this section, the variable state represents the state tree, with state.accounts[k], state.inactiveValidatorSet[k], state.activeValidatorSet[k], and state.delegationSet[k] being shorthand for the leaf in the state tree in the accounts, inactive validator set, active validator set, and delegation set subtrees with pre-hashed key k. E.g. state.accounts[a] is shorthand for state[(ACCOUNTS_SUBTREE_ID << 8*(32-STATE_SUBTREE_RESERVED_BYTES)) | ((-1 >> 8*STATE_SUBTREE_RESERVED_BYTES) & hash(a))].
State transitions are applied in the following order:
block.availableData.transactionData
Transactions are applied to the state. Note that transactions mutate the state (essentially, the validator set and minimal balances), while blobs do not.
block.availableData.transactionData is simply a list of WrappedTransactions. For each wrapped transaction in this list, wrappedTransaction, with index i (starting from 0), the following checks must be true:
wrappedTransaction.index==i.
For wrappedTransaction's transaction transaction, the following checks must be true:
transaction.signaturemust be a valid signature overtransaction.signedTransactionData.
Finally, each wrappedTransaction is processed depending on its transaction type. These are specified in the next subsections, where tx is short for transaction.signedTransactionData, and sender is the recovered signing address. We will define a few helper functions:
tipCost(y, z) = y * z
totalCost(x, y, z) = x + tipCost(y, z)
where x above is the amount of coins sent by the transaction authorizer, y above is the tip rate set in the transaction, and z above is the measure of the block space used by the transaction (i.e. size in bytes).
Four additional helper functions are defined to manage the validator queue:
-
findFromQueue(power), which returns the address of the last validator in the validator queue with voting power greater than or equal topower, or0if the queue is empty or no validators in the queue have at leastpowervoting power. -
parentFromQueue(address), which returns the address of the parent in the validator queue of the validator with addressaddress, or0ifaddressis not in the queue or is the head of the queue. -
validatorQueueInsert, defined asfunction validatorQueueInsert(validator) # Insert the new validator into the linked list parent = findFromQueue(validator.votingPower) if parent != 0 if state.accounts[parent].status == AccountStatus.ValidatorBonded validator.next = state.activeValidatorSet[parent].next state.activeValidatorSet[parent].next = sender else validator.next = state.inactiveValidatorSet[parent].next state.inactiveValidatorSet[parent].next = sender else validator.next = state.validatorQueueHead state.validatorQueueHead = sender
-
validatorQueueRemove, defined asfunction validatorQueueRemove(validator, sender) # Remove existing validator from the linked list parent = parentFromQueue(sender) if parent != 0 if state.accounts[parent].status == AccountStatus.ValidatorBonded state.activeValidatorSet[parent].next = validator.next validator.next = 0 else state.inactiveValidatorSet[parent].next = validator.next validator.next = 0 else state.validatorQueueHead = validator.next validator.next = 0
Note that light clients cannot perform a linear search through a linked list, and are instead provided logarithmic proofs (e.g. in the case of parentFromQueue, a proof to the parent is provided, which should have address as its next validator).
In addition, three helper functions to manage the blob paid list:
findFromBlobPaidList(start), which returns the transaction ID of the last transaction in the blob paid list withfinishgreater thanstart, or0if the list is empty or no transactions in the list have at leaststartfinish.parentFromBlobPaidList(txid), which returns the transaction ID of the parent in the blob paid list of the transaction with IDtxid, or0iftxidis not in the list or is the head of the list.blobPaidListInsert, defined as
function blobPaidListInsert(tx, txid)
# Insert the new transaction into the linked list
parent = findFromBlobPaidList(tx.blobStartIndex)
state.blobsPaid[txid].start = tx.blobStartIndex
numShares = ceil(tx.blobSize / SHARE_SIZE)
state.blobsPaid[txid].finish = tx.blobStartIndex + numShares - 1
if parent != 0
state.blobsPaid[txid].next = state.blobsPaid[parent].next
state.blobsPaid[parent].next = txid
else
state.blobsPaid[txid].next = state.blobPaidHead
state.blobPaidHead = txid
We define a helper function to compute F1 entries:
function compute_new_entry(reward, power)
if power == 0
return 0
return reward // power
After applying a transaction, the new state root is computed.
SignedTransactionDataTransfer
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.Transfer.totalCost(tx.amount, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(tx.amount, tx.fee.tipRate, bytesPaid)
state.accounts[tx.to].balance += tx.amount
state.activeValidatorSet.proposerBlockReward += tipCost(bytesPaid)
SignedTransactionDataMsgPayForData
bytesPaid = len(tx) + tx.blobSize
currentStartFinish = state.blobsPaid[findFromBlobPaidList(tx.blobStartIndex)]
parentStartFinish = state.blobsPaid[parentFromBlobPaidList(findFromBlobPaidList(tx.blobStartIndex))]
The following checks must be true:
tx.type==TransactionType.MsgPayForData.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.- The
ceil(tx.blobSize / SHARE_SIZE)shares starting at indextx.blobStartIndexmust:- Have namespace
tx.blobNamespace.
- Have namespace
tx.blobShareCommitment== computed as described in the MsgPayForData section.parentStartFinish.finish<tx.blobStartIndex.currentStartFinish.start==0orcurrentStartFinish.start>tx.blobStartIndex + ceil(tx.blobSize / SHARE_SIZE).
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(tx.amount, tx.fee.tipRate, bytesPaid)
blobPaidListInsert(tx, id(tx))
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataCreateValidator
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.CreateValidator.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.tx.commissionRate.denominator > 0.tx.commissionRate.numerator <= tx.commissionRate.denominator.state.accounts[sender].status==AccountStatus.None.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
state.accounts[sender].status = AccountStatus.ValidatorQueued
validator = new Validator
validator.commissionRate = tx.commissionRate
validator.delegatedCount = 0
validator.votingPower = 0
validator.pendingRewards = 0
validator.latestEntry = PeriodEntry(0)
validator.unbondingHeight = 0
validator.isSlashed = false
validatorQueueInsert(validator)
state.inactiveValidatorSet[sender] = validator
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataBeginUnbondingValidator
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.BeginUnbondingValidator.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[sender].status==AccountStatus.ValidatorQueuedorstate.accounts[sender].status==AccountStatus.ValidatorBonded.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
state.accounts[sender].status = ValidatorStatus.Unbonding
if state.accounts[sender].status == AccountStatus.ValidatorQueued
validator = state.inactiveValidatorSet[sender]
else if state.accounts[sender].status == AccountStatus.ValidatorBonded
validator = state.activeValidatorSet[sender]
delete state.activeValidatorSet[sender]
validator.unbondingHeight = block.height + 1
validator.latestEntry += compute_new_entry(validator.pendingRewards, validator.votingPower)
validator.pendingRewards = 0
validatorQueueRemove(validator, sender)
state.inactiveValidatorSet[sender] = validator
state.activeValidatorSet.activeVotingPower -= validator.votingPower
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataUnbondValidator
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.UnbondValidator.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[sender].status==AccountStatus.ValidatorUnbonding.state.inactiveValidatorSet[sender].unbondingHeight + UNBONDING_DURATION<block.height.
Apply the following to the state:
validator = state.inactiveValidatorSet[sender]
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
state.accounts[sender].status = AccountStatus.ValidatorUnbonded
state.accounts[sender].balance += validator.commissionRewards
state.inactiveValidatorSet[sender] = validator
if validator.delegatedCount == 0
state.accounts[sender].status = AccountStatus.None
delete state.inactiveValidatorSet[sender]
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataCreateDelegation
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.CreateDelegation.totalCost(tx.amount, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.state.accounts[tx.to].status==AccountStatus.ValidatorQueuedorstate.accounts[tx.to].status==AccountStatus.ValidatorBonded.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[sender].status==AccountStatus.None.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(tx.amount, tx.fee.tipRate, bytesPaid)
state.accounts[sender].status = AccountStatus.DelegationBonded
if state.accounts[tx.to].status == AccountStatus.ValidatorQueued
validator = state.inactiveValidatorSet[tx.to]
else if state.accounts[tx.to].status == AccountStatus.ValidatorBonded
validator = state.activeValidatorSet[tx.to]
delegation = new Delegation
delegation.status = DelegationStatus.Bonded
delegation.validator = tx.to
delegation.stakedBalance = tx.amount
delegation.beginEntry = validator.latestEntry
delegation.endEntry = PeriodEntry(0)
delegation.unbondingHeight = 0
validator.latestEntry += compute_new_entry(validator.pendingRewards, validator.votingPower)
validator.pendingRewards = 0
validator.delegatedCount += 1
validator.votingPower += tx.amount
# Update the validator in the linked list by first removing then inserting
validatorQueueRemove(validator, delegation.validator)
validatorQueueInsert(validator)
state.delegationSet[sender] = delegation
if state.accounts[tx.to].status == AccountStatus.ValidatorQueued
state.inactiveValidatorSet[tx.to] = validator
else if state.accounts[tx.to].status == AccountStatus.ValidatorBonded
state.activeValidatorSet[tx.to] = validator
state.activeValidatorSet.activeVotingPower += tx.amount
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataBeginUnbondingDelegation
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.BeginUnbondingDelegation.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[sender].status==AccountStatus.DelegationBonded.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
state.accounts[sender].status = AccountStatus.DelegationUnbonding
delegation = state.delegationSet[sender]
if state.accounts[delegation.validator].status == AccountStatus.ValidatorQueued ||
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonding ||
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonded
validator = state.inactiveValidatorSet[delegation.validator]
else if state.accounts[delegation.validator].status == AccountStatus.ValidatorBonded
validator = state.activeValidatorSet[delegation.validator]
delegation.status = DelegationStatus.Unbonding
delegation.endEntry = validator.latestEntry
delegation.unbondingHeight = block.height + 1
validator.latestEntry += compute_new_entry(validator.pendingRewards, validator.votingPower)
validator.pendingRewards = 0
validator.delegatedCount -= 1
validator.votingPower -= delegation.stakedBalance
# Update the validator in the linked list by first removing then inserting
# Only do this if the validator is actually in the queue (i.e. bonded or queued)
if state.accounts[delegation.validator].status == AccountStatus.ValidatorBonded ||
state.accounts[delegation.validator].status == AccountStatus.ValidatorQueued
validatorQueueRemove(validator, delegation.validator)
validatorQueueInsert(validator)
state.delegationSet[sender] = delegation
if state.accounts[delegation.validator].status == AccountStatus.ValidatorQueued ||
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonding ||
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonded
state.inactiveValidatorSet[delegation.validator] = validator
else if state.accounts[delegation.validator].status == AccountStatus.ValidatorBonded
state.activeValidatorSet[delegation.validator] = validator
state.activeValidatorSet.activeVotingPower -= delegation.stakedBalance
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataUnbondDelegation
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.UnbondDelegation.totalCost(0, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[sender].status==AccountStatus.DelegationUnbonding.state.delegationSet[sender].unbondingHeight + UNBONDING_DURATION<block.height.
Apply the following to the state:
delegation = state.accounts[sender].delegationInfo
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
state.accounts[sender].status = None
# Return the delegated stake
state.accounts[sender].balance += delegation.stakedBalance
# Also disperse rewards (commission has already been levied)
state.accounts[sender].balance += delegation.stakedBalance * (delegation.endEntry - delegation.beginEntry)
if state.accounts[delegation.validator].status == AccountStatus.ValidatorQueued ||
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonding
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonded
validator = state.inactiveValidatorSet[delegation.validator]
else if state.accounts[delegation.validator].status == AccountStatus.ValidatorBonded
validator = state.activeValidatorSet[delegation.validator]
if validator.delegatedCount == 0 &&
state.accounts[delegation.validator].status == AccountStatus.ValidatorUnbonded
state.accounts[delegation.validator].status = AccountStatus.None
delete state.inactiveValidatorSet[delegation.validator]
delete state.accounts[sender].delegationInfo
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionDataBurn
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.Burn.totalCost(tx.amount, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(tx.amount, tx.fee.tipRate, bytesPaid)
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionRedelegateCommission
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.RedelegateCommission.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[tx.to].status==AccountStatus.DelegationBonded.state.accounts[sender].status==AccountStatus.ValidatorBonded.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
delegation = state.delegationSet[tx.to]
validator = state.activeValidatorSet[delegation.validator]
# Force-redelegate pending rewards for delegation
pendingRewards = delegation.stakedBalance * (validator.latestEntry - delegation.beginEntry)
delegation.stakedBalance += pendingRewards
delegation.beginEntry = validator.latestEntry
validator.latestEntry += compute_new_entry(validator.pendingRewards, validator.votingPower)
validator.pendingRewards = 0
# Assign pending commission rewards to delegation
commissionRewards = validator.commissionRewards
delegation.stakedBalance += commissionRewards
validator.commissionRewards = 0
# Update voting power
validator.votingPower += pendingRewards + commissionRewards
state.activeValidatorSet.activeVotingPower += pendingRewards + commissionRewards
state.delegationSet[tx.to] = delegation
state.activeValidatorSet[delegation.validator] = validator
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
SignedTransactionRedelegateReward
bytesPaid = len(tx)
The following checks must be true:
tx.type==TransactionType.RedelegateReward.totalCost(0, tx.fee.tipRate, bytesPaid)<=state.accounts[sender].balance.tx.nonce==state.accounts[sender].nonce + 1.state.accounts[sender].status==AccountStatus.DelegationBonded.state.accounts[state.delegationSet[sender].validator].status==AccountStatus.ValidatorBonded.
Apply the following to the state:
state.accounts[sender].nonce += 1
state.accounts[sender].balance -= totalCost(0, tx.fee.tipRate, bytesPaid)
delegation = state.delegationSet[sender]
validator = state.activeValidatorSet[delegation.validator]
# Redelegate pending rewards for delegation
pendingRewards = delegation.stakedBalance * (validator.latestEntry - delegation.beginEntry)
delegation.stakedBalance += pendingRewards
delegation.beginEntry = validator.latestEntry
validator.latestEntry += compute_new_entry(validator.pendingRewards, validator.votingPower)
validator.pendingRewards = 0
# Update voting power
validator.votingPower += pendingRewards
state.activeValidatorSet.activeVotingPower += pendingRewards
state.delegationSet[sender] = delegation
state.activeValidatorSet[delegation.validator] = validator
state.activeValidatorSet.proposerBlockReward += tipCost(tx.fee.tipRate, bytesPaid)
Begin Block
At the beginning of the block, rewards are distributed to the block proposer.
Apply the following to the state:
proposer = state.activeValidatorSet[block.header.proposerAddress]
# Compute block subsidy and save to state for use in end block.
rewardFactor = (TARGET_ANNUAL_ISSUANCE * BLOCK_TIME) / (SECONDS_PER_YEAR * sqrt(GENESIS_COIN_COUNT))
blockReward = rewardFactor * sqrt(state.activeValidatorSet.activeVotingPower)
state.activeValidatorSet.proposerBlockReward = blockReward
# Save proposer's initial voting power to state for use in end block.
state.activeValidatorSet.proposerInitialVotingPower = proposer.votingPower
state.activeValidatorSet[block.header.proposerAddress] = proposer
End Block
Apply the following to the state:
account = state.accounts[block.header.proposerAddress]
if account.status == AccountStatus.ValidatorUnbonding
account.status == AccountStatus.ValidatorUnbonded
proposer = state.inactiveValidatorSet[block.header.proposerAddress]
else if account.status == AccountStatus.ValidatorBonded
proposer = state.activeValidatorSet[block.header.proposerAddress]
# Flush the outstanding pending rewards.
proposer.latestEntry += compute_new_entry(proposer.pendingRewards, proposer.votingPower)
proposer.pendingRewards = 0
blockReward = state.activeValidatorSet.proposerBlockReward
commissionReward = proposer.commissionRate.numerator * blockReward // proposer.commissionRate.denominator
proposer.commissionRewards += commissionReward
proposer.pendingRewards += blockReward - commissionReward
# Even though the voting power hasn't changed yet, we consider this a period change.
proposer.latestEntry += compute_new_entry(proposer.pendingRewards, state.activeValidatorSet.proposerInitialVotingPower)
proposer.pendingRewards = 0
if account.status == AccountStatus.ValidatorUnbonding
account.status == AccountStatus.ValidatorUnbonded
state.inactiveValidatorSet[block.header.proposerAddress] = proposer
else if account.status == AccountStatus.ValidatorBonded
state.activeValidatorSet[block.header.proposerAddress] = proposer
At the end of a block, the top MAX_VALIDATORS validators by voting power with voting power greater than zero are or become active (bonded). For newly-bonded validators, the entire validator object is moved to the active validators subtree and their status is changed to bonded. For previously-bonded validators that are no longer in the top MAX_VALIDATORS validators begin unbonding.
Bonding validators is simply setting their status to AccountStatus.ValidatorBonded. The logic for validator unbonding is found in the BeginUnbondingValidator section, minus transaction sender updates (nonce, balance, and fee).
This end block implicit state transition is a single state transition, and only has a single intermediate state root associated with it.
Content Addressable Transaction Pool Specification
- 01.12.2022 | Initial specification (@cmwaters)
- 09.12.2022 | Add Push/Pull mechanics (@cmwaters)
Outline
This document specifies the properties, design and implementation of a content addressable transaction pool (CAT). This protocol is intended as an alternative to the FIFO and Priority mempools currently built-in to the Tendermint consensus protocol. The term content-addressable here, indicates that each transaction is identified by a smaller, unique tag (in this case a sha256 hash). These tags are broadcast among the transactions as a means of more compactly indicating which peers have which transactions. Tracking what each peer has aims at reducing the amount of duplication. In a network without content tracking, a peer may receive as many duplicate transactions as peers connected to. The tradeoff here therefore is that the transactions are significantly larger than the tag such that the sum of the data saved sending what would be duplicated transactions is larger than the sum of sending each peer a tag.
Purpose
The objective of such a protocol is to transport transactions from the author (usually a client) to a proposed block, optimizing both latency and throughput i.e. how quickly can a transaction be proposed (and committed) and how many transactions can be transported into a block at once.
Typically the mempool serves to receive inbound transactions via an RPC endpoint, gossip them to all nodes in the network (regardless of whether they are capable of proposing a block or not), and stage groups of transactions to both consensus and the application to be included in a block.
Assumptions
The following are assumptions inherited from existing Tendermint mempool protocols:
CheckTxshould be seen as a simple gatekeeper to what transactions enter the pool to be gossiped and staged. It is non-deterministic: one node may reject a transaction that another node keeps.- Applications implementing
CheckTxare responsible for replay protection (i.e. the same transaction being present in multiple blocks). The mempool ensures that within the same block, no duplicate transactions can exist. - The underlying p2p layer guarantees eventually reliable broadcast. A transaction need only be sent once to eventually reach the target peer.
Messages
The CAT protocol extends on the existing mempool implementations by introducing two new protobuf messages:
message SeenTx {
bytes tx_key = 1;
optional string from = 2;
}
message WantTx {
bytes tx_key = 1;
}
Both SeenTx and WantTx contain the sha256 hash of the raw transaction bytes. SeenTx also contains an optional p2p.ID that corresponds to the peer that the node received the tx from. The only validation for both is that the byte slice of the tx_key MUST have a length of 32.
Both messages are sent across a new channel with the ID: byte(0x31). This enables cross compatibility as discussed in greater detail below.
Note: The term
SeenTxis used over the more commonHasTxbecause the transaction pool contains sophisticated eviction logic. TTLs, higher priority transactions and reCheckTx may mean that a transaction pool had a transaction but does not have it any more. Semantically it's more appropriate to useSeenTxto imply not the presence of a transaction but that the node has seen it and dealt with it accordingly.
Outbound logic
A node in the protocol has two distinct modes: "broadcast" and "request/response". When a node receives a transaction via RPC (or specifically through CheckTx), it assumed that it is the only recipient from that client and thus will immediately send that transaction, after validation, to all connected peers. Afterwards, only "request/response" is used to disseminate that transaction to everyone else.
Note: Given that one can configure a mempool to switch off broadcast, there are no guarantees when a client submits a transaction via RPC and no error is returned that it will find its way into a proposers transaction pool.
A SeenTx is broadcasted to ALL nodes upon receiving a "new" transaction from a peer. The transaction pool does not need to track every unique inbound transaction, therefore "new" is identified as:
- The node does not currently have the transaction
- The node did not recently reject the transaction or has recently seen the same transaction committed (subject to the size of the cache)
- The node did not recently evict the transaction (subject to the size of the cache)
Given this criteria, it is feasible, yet unlikely that a node receives two SeenTx messages from the same peer for the same transaction.
A SeenTx MAY be sent for each transaction currently in the transaction pool when a connection with a peer is first established. This acts as a mechanism for syncing pool state across peers.
The SeenTx message MUST only be broadcasted after validation and storage. Although it is possible that a node later drops a transaction under load shedding, a SeenTx should give as strong guarantees as possible that the node can be relied upon by others that don't yet have the transaction to obtain it.
Note: Inbound transactions submitted via the RPC do not trigger a
SeenTxmessage as it is assumed that the node is the first to see the transaction and by gossiping it to others it is implied that the node has seen the transaction.
A WantTx message is always sent point to point and never broadcasted. A WantTx MUST only be sent after receiving a SeenTx message from that peer. There is one exception which is that a WantTx MAY also be sent by a node after receiving an identical WantTx message from a peer that had previously received the nodes SeenTx but which after the lapse in time, did no longer exist in the nodes transaction pool. This provides an optional synchronous method for communicating that a node no longer has a transaction rather than relying on the defaulted asynchronous approach which is to wait for a period of time and try again with a new peer.
WantTx must be tracked. A node SHOULD not send multiple WantTxs to multiple peers for the same transaction at once but wait for a period that matches the expected network latency before rerequesting the transaction to another peer.
Inbound logic
Transaction pools are solely run in-memory; thus when a node stops, all transactions are discarded. To avoid the scenario where a node restarts and does not receive transactions because other nodes recorded a SeenTx message from their previous run, each transaction pool should track peer state based per connection and not per NodeID.
Upon receiving a Txs message:
- Check whether it is in response to a request or simply an unsolicited broadcast
- Validate the tx against current resources and the applications
CheckTx - If rejected or evicted, mark accordingly
- If successful, send a
SeenTxmessage to all connected peers excluding the original sender. If it was from an initial broadcast, theSeenTxshould populate theFromfield with thep2p.IDof the recipient else if it is in response to a requestFromshould remain empty.
Upon receiving a SeenTx message:
- It should mark the peer as having seen the message.
- If the node has recently rejected that transaction, it SHOULD ignore the message.
- If the node already has the transaction, it SHOULD ignore the message.
- If the node does not have the transaction but recently evicted it, it MAY choose to rerequest the transaction if it has adequate resources now to process it.
- If the node has not seen the transaction or does not have any pending requests for that transaction, it can do one of two things:
- It MAY immediately request the tx from the peer with a
WantTx. - If the node is connected to the peer specified in
FROM, it is likely, from a non-byzantine peer, that the node will also shortly receive the transaction from the peer. It MAY wait for aTxsmessage for a bounded amount of time but MUST eventually send aWantTxmessage to either the original peer or any other peer that has the specified transaction.
- It MAY immediately request the tx from the peer with a
Upon receiving a WantTx message:
- If it has the transaction, it MUST respond with a
Txsmessage containing that transaction. - If it does not have the transaction, it MAY respond with an identical
WantTxor rely on the timeout of the peer that requested the transaction to eventually ask another peer.
Compatibility
CAT has Go API compatibility with the existing two mempool implementations. It implements both the Reactor interface required by Tendermint's P2P layer and the Mempool interface used by consensus and rpc. CAT is currently network compatible with existing implementations (by using another channel), but the protocol is unaware that it is communicating with a different mempool and that SeenTx and WantTx messages aren't reaching those peers thus it is recommended that the entire network use CAT.
Honest Block Proposer
This document describes the tasks of an honest block proposer to assemble a new block. Performing these actions is not enforced by the consensus rules, so long as a valid block is produced.
Constructing a Block
Before arranging available data into shares, the block proposer must select which transactions to include and determine the size of the original data square.
There are two restrictions on the original data's square size:
- It must be at most
AVAILABLE_DATA_ORIGINAL_SQUARE_MAX. - It must be a power of 2.
With these restrictions in mind, the block proposer performs the following actions:
- Initialize a square builder with the maximum effective square size (the lesser of the
GovMaxSquareSizegovernance parameter and theAVAILABLE_DATA_ORIGINAL_SQUARE_MAXupper bound). - Separate the available transactions from the mempool into normal transactions and blob transactions. Filter out any transactions that exceed the maximum transaction size.
- Iterate through normal transactions and attempt to add each one to the square:
- If adding the transaction would cause the total share count to exceed the maximum square capacity, skip it.
- Validate the transaction (e.g. signature verification, fee checks). If validation fails, revert the addition and skip it.
- Iterate through blob transactions and attempt to add each one to the square:
- If adding the blob transaction (including its blobs and padding required by share commitment rules) would cause the total share count to exceed the maximum square capacity, skip it.
- Validate the transaction. If validation fails, revert the addition and skip it.
- Compute the smallest square size that is a power of 2 that can fit all the accepted transactions and blobs (including any padding between blobs).
- Sort blobs by namespace (preserving the mempool-provided order of blobs within the same namespace, which is based on sender-aggregated priority).
- Write out the final square: normal transaction shares, then pay-for-blob transaction shares, then reserved padding, then blob shares (with inter-blob padding as needed), then tail padding.
Block Validity Rules
Introduction
Unlike most blockchains, Celestia derives most of its functionality from stateless commitments to data rather than stateful transitions. This means that the protocol relies heavily on block validity rules. Notably, resource constrained light clients must be able to detect when a subset of these validity rules have not been followed in order to avoid making an honest majority assumption on the consensus network. This has a significant impact on their design. More information on how light clients can check the invalidity of a block can be found in the Fraud Proofs spec.
Note Celestia relies on CometBFT (formerly tendermint) for consensus, meaning that it has single slot finality and is fork-free. Therefore, in order to ensure that an invalid block is never committed to, each validator must check that each block follows all validity rules before voting. If over two thirds of the voting power colludes to break a validity rule, then fraud proofs are created for light clients. After light clients verify fraud proofs, they halt.
Validity Rules
Before any Celestia specific validation is performed, all CometBFT block validation rules must be followed.
Notably, this includes verifying data availability. Consensus nodes verify data availability by simply downloading the entire block.
Note Light clients only sample a fraction of the block. More details on how sampling actually works can be found in the seminal "Fraud and Data Availability Proofs: Maximising Light Client Security and Scaling Blockchains with Dishonest Majorities" and in the
celestia-noderepo.
Celestia specific validity rules can be categorized into multiple groups:
Block Rules
- In
Block.Data.Txs, allBlobTxtransactions must be ordered after non-BlobTxtransactions.
Transaction Validity Rules
App Version 1
There is no validity rule that transactions must be decodable so the following rules only apply to transactions that are decodable.
- Decodable transactions must pass all AnteHandler checks.
- Decodable non-
BlobTxtransactions must not contain aMsgPayForBlobsmessage. - Decodable
BlobTxtransactions must be valid according to the BlobTx validity rules.
App Version 2
- All transactions must be decodable.
- All transactions must pass all AnteHandler checks.
- Non-
BlobTxtransactions must not contain aMsgPayForBlobsmessage. BlobTxtransactions must be valid according to the BlobTx validity rules.
Data Root Construction
The data root must be calculated from a correctly constructed data square per the data square layout rules.
AnteHandler
Celestia makes use of a Cosmos SDK AnteHandler in order to reject decodable sdk.Txs that do not meet certain criteria. The AnteHandler is invoked at multiple times during the transaction lifecycle:
CheckTxprior to the transaction entering the mempoolPrepareProposalwhen the block proposer includes the transaction in a block proposalProcessProposalwhen validators validate the transaction in a block proposalDeliverTxwhen full nodes execute the transaction in a decided block
The AnteHandler is defined in app/ante/ante.go. The app version impacts AnteHandler behavior. See:
- AnteHandler v1
- AnteHandler v2
- AnteHandler v3
- AnteHandler v4
- AnteHandler v5
- AnteHandler v6
- AnteHandler v7
- AnteHandler v8
- AnteHandler v9
- AnteHandler v10
AnteHandler v1
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 1:
- The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) andgasPerBlobByteis a governance parameter that can be modified (theDefaultGasPerBlobByte = 8). - The tx's total blob size is <= the max blob size. The max blob size is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v2
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 2:
- The tx does not contain any messages that are unsupported by the current app version. See
MsgVersioningGateKeeper. - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) andgasPerBlobByteis a governance parameter that can be modified (theDefaultGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v3
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 3:
- The tx does not contain any messages that are unsupported by the current app version. See
MsgVersioningGateKeeper. - The
sdk.Txsize is not larger than the application's configured versioned constant MaxTxSize. This limit does not apply to blobs. - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) andgasPerBlobByteis a versioned constant that can be modified through hard forks (theDefaultGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v4
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 4:
- The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) andgasPerBlobByteis a versioned constant that can be modified through hard forks (theDefaultGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade).
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v5
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 5:
- The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) andgasPerBlobByteis a versioned constant that can be modified through hard forks (theDefaultGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade).
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v6
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 6:
- Panics are wrapped with the transaction string format for better error reporting.
- A gas meter is set up in the context before any gas consumption occurs.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade). - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - Public keys are set in the context for the fee-payer and all signers.
- The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) from the go-square package andgasPerBlobByteis a versioned constant that can be modified through hard forks (theGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v7
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 7:
- Panics are wrapped with the transaction string format for better error reporting.
- A gas meter is set up in the context before any gas consumption occurs.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade). - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - Public keys are set in the context for the fee-payer and all signers.
- The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) from the go-square package andgasPerBlobByteis a versioned constant that can be modified through hard forks (theGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v8
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 8:
- Panics are wrapped with the transaction string format for better error reporting.
- A gas meter is set up in the context before any gas consumption occurs.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade). - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - Public keys are set in the context for the fee-payer and all signers.
- The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) from the go-square package andgasPerBlobByteis a versioned constant that can be modified through hard forks (theGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v9
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 9:
- Panics are wrapped with the transaction string format for better error reporting.
- A gas meter is set up in the context before any gas consumption occurs.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade). - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - Public keys are set in the context for the fee-payer and all signers.
- The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) from the go-square package andgasPerBlobByteis a versioned constant that can be modified through hard forks (theGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
AnteHandler v10
The AnteHandler chains together several decorators to ensure the following criteria are met for app version 10:
- Panics are wrapped with the transaction string format for better error reporting.
- A gas meter is set up in the context before any gas consumption occurs.
- The tx does not contain any messages that are disabled by the circuit breaker (e.g.
MsgSoftwareUpgrade,MsgCancelUpgrade,MsgIBCSoftwareUpgrade). - The tx does not contain any extension options.
- The tx passes
ValidateBasic(). - The tx's timeout_height has not been reached if one is specified.
- The tx's memo is <= the max memo characters where
MaxMemoCharacters = 256. - The tx's gas_limit is > the gas consumed based on the tx's size where
TxSizeCostPerByte = 10. - The tx's feepayer has enough funds to pay fees for the tx. The tx's feepayer is the feegranter (if specified) or the tx's first signer. Note the feegrant module is enabled.
- The tx's gas price is >= the network minimum gas price where
NetworkMinGasPrice = 0.000001utia. - Public keys are set in the context for the fee-payer and all signers.
- The tx's count of signatures <= the max number of signatures. The max number of signatures is
TxSigLimit = 7. - The tx's gas_limit is > the gas consumed based on the tx's signatures.
- The tx's signatures are valid. For each signature, ensure that the signature's sequence number (a.k.a nonce) matches the account sequence number of the signer.
- The tx does not contain a
MsgExecwith a nestedMsgExecorMsgPayForBlobs. - The tx's gas_limit is > the gas consumed based on the blob size(s). Since blobs are charged based on the number of shares they occupy, the gas consumed is calculated as follows:
gasToConsume = sharesNeeded(blob) * bytesPerShare * gasPerBlobByte. WherebytesPerShareis a global constant (an alias forShareSize = 512) from the go-square package andgasPerBlobByteis a versioned constant that can be modified through hard forks (theGasPerBlobByte = 8). - The tx's total blob share count is <= the max blob share count. The max blob share count is derived from the maximum valid square size. The max valid square size is the minimum of:
GovMaxSquareSizeandSquareSizeUpperBound. - The tx does not contain a message of type MsgSubmitProposal with zero proposal messages or with a proposal message that modifies a parameter that is not governance modifiable.
- The tx is not an IBC packet or update message that has already been processed.
In addition to the above criteria, the AnteHandler also has a number of side-effects:
- Tx fees are deducted from the tx's feepayer and added to the fee collector module account.
- Tx priority is calculated based on the smallest denomination of gas price in the tx and set in context.
- The nonce of all tx signers is incremented by 1.
Fraud Proofs
Bad Encoding Fraud Proofs
In order for data availability sampling to work, light clients must be convinced that erasure encoded parity data was encoded correctly. For light clients, this is ultimately enforced via bad encoding fraud proofs (BEFPs). Consensus nodes must verify this themselves before considering a block valid. This is done automatically by verifying the data root of the header, since that requires reconstructing the square from the block data, performing the erasure encoding, calculating the data root using that representation, and then comparing the data root found in the header.
Blob Inclusion
TODO
State
State fraud proofs allow light clients to avoid making an honest majority assumption for state validity. While these are not incorporated into the protocol as of v1.0.0, there are example implementations that can be found in Rollkit. More info in rollkit-ADR009.
Networking
Wire Format
AvailableData
| name | type | description |
|---|---|---|
availableDataRows | AvailableDataRow[] | List of rows. |
AvailableDataRow
| name | type | description |
|---|---|---|
shares | Share[] | Shares in a row. |
Invalid Erasure Coding
If a malicious block producer incorrectly computes the 2D Reed-Solomon code for a block's data, a fraud proof for this can be presented. We assume that the light clients have the AvailableDataHeader and the Header for each block. Hence, given a ShareProof, they can verify if the rowRoot or colRoot specified by isCol and position commits to the corresponding Share. Similarly, given the height of a block, they can access all elements within the AvailableDataHeader and the Header of the block.
ShareProof
| name | type | description |
|---|---|---|
share | Share | The share. |
proof | NamespaceMerkleTreeInclusionProof | The Merkle proof of the share in the offending row or column root. |
isCol | bool | A Boolean indicating if the proof is from a row root or column root; false if it is a row root. |
position | uint64 | The index of the share in the offending row or column. |
Invalid State Update
If a malicious block producer incorrectly computes the state, a fraud proof for this can be presented. We assume that the light clients have the AvailableDataHeader and the Header for each block. Hence, given a ShareProof, they can verify if the rowRoot or colRoot specified by isCol and position commits to the corresponding Share. Similarly, given the height of a block, they can access all elements within the AvailableDataHeader and the Header of the block.
Public-Key Cryptography
Consensus-critical data is authenticated using ECDSA with the curves: Secp256k1 or Ed25519.
Secp256k1
The Secp256k1 key type is used by accounts that submit transactions to be included in Celestia.
Libraries
A highly-optimized library is available in C (https://github.com/bitcoin-core/secp256k1), with wrappers in Go (https://pkg.go.dev/github.com/ethereum/go-ethereum/crypto/secp256k1) and Rust (https://docs.rs/crate/secp256k1).
Public-keys
Secp256k1 public keys can be compressed to 257-bits (or 33 bytes) per the format described in the Cosmos SDK accounts documentation.
Addresses
Cosmos addresses are 20 bytes in length.
Signatures
Deterministic signatures (RFC-6979) should be used when signing, but this is not enforced at the protocol level as it cannot be for Secp256k1 signatures.
Signatures are represented as the r and s (each 32 bytes) values of the signature. r and s take on their usual meaning (see: SEC 1, 4.1.3 Signing Operation). Signatures are encoded with protobuf as described in the encoding documentation.
Human Readable Encoding
In front-ends addresses are prefixed with the Bech32 prefix celestia. For example, a valid address is celestia1kj39jkzqlr073t42am9d8pd40tgudc3e2kj9yf.
Ed25519
The Ed25519 key type is used by validators.
Libraries
Public Keys
Ed25519 public keys are 32 bytes in length. They often appear in validator configuration files (e.g. genesis.json) base64 encoded:
"pub_key": {
"type": "tendermint/PubKeyEd25519",
"value": "DMEMMj1+thrkUCGocbvvKzXeaAtRslvX9MWtB+smuIA="
}
Addresses
Ed25519 addresses are the first 20-bytes of the SHA256 hash of the raw 32-byte public key:
address = SHA256(pubkey)[:20]
Signatures
Ed25519 signatures are 64 bytes in length.
Data Square Layout
Preamble
Celestia uses a data availability scheme that allows nodes to determine whether a block's data was published without downloading the whole block. The core of this scheme is arranging data in a two-dimensional matrix of shares, then applying erasure coding to each row and column. This document describes the rationale for how data—transactions, blobs, and other data—is actually arranged. Familiarity with the originally proposed data layout format is assumed.
Layout Rationale
Block data consists of:
- Standard cosmos-SDK transactions: (which are often represented internally as the
sdk.Txinterface) as described in cosmos-sdk ADR020- These transactions contain protobuf encoded
sdk.Msgs, which get executed atomically (if one fails they all fail) to update the Celestia state. The complete list of modules, which define thesdk.Msgs that the state machine is capable of handling, can be found in the state machine modules spec. Examples include standard cosmos-sdk module messages such as MsgSend, and celestia specific module messages such asMsgPayForBlobs
- These transactions contain protobuf encoded
- Blobs: binary large objects which do not modify the Celestia state, but which are intended for a Celestia application identified with a provided namespace.
We want to arrange this data into a k * k matrix of fixed-sized shares, which will later be committed to in Namespace Merkle Trees (NMTs) so that individual shares in this matrix can be proven to belong to a single data root. k must always be a power of 2 (e.g. 1, 2, 4, 8, 16, 32, etc.) as this is optimal for the erasure coding algorithm.
The simplest way we can imagine arranging block data is to simply serialize it all in no particular order, split it into fixed-sized shares, then arrange those shares into the k * k matrix in row-major order. However, this naive scheme can be improved in a number of ways, described below.
First, we impose some ground rules:
- Data must be ordered by namespace. This makes queries into a NMT commitment of that data more efficient.
- Since non-blob data are not naturally intended for particular namespaces, we assign reserved namespaces for them. A range of namespaces is reserved for this purpose, starting from the lowest possible namespace.
- By construction, the above two rules mean that non-blob data always precedes blob data in the row-major matrix, even when considering single rows or columns.
- Data with different namespaces must not be in the same share. This might cause a small amount of wasted block space, but makes the NMT easier to reason about in general since leaves are guaranteed to belong to a single namespace.
Given these rules, a square may look as follows:

Padding is addressed in the padding section. Namespace C contains two blobs of two shares each while Namespace D contains one blob of three shares.
Ordering
The order of blobs in a namespace is determined by the order that transactions are provided to PrepareProposal, which is the order they are reaped from the mempool. The CAT mempool groups transactions by signer and orders these groups by a gas-weighted average priority (where priority is derived from the gas-price = fee/gas). Within a signer's group, transactions are ordered by sequence number. As a result, blobs from a higher-priority signer group generally appear before blobs from a lower-priority group within the same namespace. However, this is not strict per-transaction priority ordering: if a single signer has transactions with varying gas prices, the averaging can cause a high-priority transaction to appear after a lower-priority transaction from a different signer (see celestia-core CAT mempool for details).
Blob Share Commitment Rules
Transactions can pay fees for a blob to be included in the same block as the transaction itself. It may seem natural to bundle the MsgPayForBlobs transaction that pays for a number of blobs with these blobs (which is the case in other blockchains with native execution, e.g. calldata in Ethereum transactions or OP_RETURN data in Bitcoin transactions), however this would mean that processes validating the state of the Celestia network would need to download all blob data. PayForBlob transactions must therefore only include a commitment to (i.e. some hash of) the blob they pay fees for. If implemented naively (e.g. with a simple hash of the blob, or a simple binary Merkle tree root of the blob), this can lead to a data availability problem, as there are no guarantees that the data behind these commitments is actually part of the block data.
To that end, we impose some additional rules onto blobs only: blobs must be placed in a way such that both the transaction sender and the block producer can be held accountable—a necessary property for e.g. fee burning. Accountable in this context means that
- The transaction sender must pay sufficient fees for blob inclusion.
- The block proposer cannot claim that a blob was included when it was not (which implies that a transaction and the blob it pays for must be included in the same block). In addition all blobs must be accompanied by a PayForBlob transaction.
Specifically, a MsgPayForBlobs must include a ShareCommitment over the contents of each blob it is paying for. If the transaction sender knows 1) k, the size of the matrix, 2) the starting location of their blob in a row, and 3) the length of the blob (they know this since they are sending the blob), then they can actually compute a sequence of roots to subtrees in the row NMTs. Taking the simple Merkle root of these subtree roots provides us with the ShareCommitment that gets included in MsgPayForBlobs. Using subtree roots instead of all the leaves makes blob inclusion proofs smaller.

Understanding 1) and 2) would usually require interaction with the block proposer. To make the possible starting locations of blobs sufficiently predictable and to make ShareCommitment independent of k, we impose an additional rule. The blob must start at a multiple of the SubtreeWidth.
The SubtreeWidth is calculated as the length of the blob in shares, divided by the SubtreeRootThreshold and rounded up to the nearest power of 2 (implementation here). If the output is greater than the minimum square size that the blob can fit in (i.e. a blob of 15 shares has a minimum square size of 4) then we take that minimum value. This SubtreeWidth is used as the width of the first mountain in the Merkle Mountain Range that would all together represent the ShareCommitment over the blob.

The SubtreeRootThreshold is an arbitrary versioned protocol constant that aims to put a soft limit on the number of subtree roots included in a blob inclusion proof, as described in ADR013. A higher SubtreeRootThreshold means less padding and more tightly packed squares but also means greater blob inclusion proof sizes.
With the above constraint, we can compute subtree roots deterministically. For example, a blob of 172 shares and SubtreeRootThreshold (SRT) = 64, must start on a share index that is a multiple of 4 because 172/64 = 3. 3 rounded up to the nearest power of 2 is 4. In this case, there will be a maximum of 3 shares of padding between blobs (more on padding below). The maximum subtree width in shares for the first mountain in the Merkle range will be 4 (The actual mountain range would be 43 subtree roots of 4 shares each). The ShareCommitment is then the Merkle tree over the peaks of the mountain range.
Padding
Given these rules whereby blobs in their share format can't be directly appended one after the other, we use padding shares to fill the gaps. These are shares with a particular format (see padding). Padding always comes after all the blobs in the namespace. The padding at the end of the reserved namespace and at the end of the square are special in that they belong to unique namespaces. All other padding shares use the namespace of the blob before it in the data square.
Resource Pricing
For all standard cosmos-sdk transactions (staking, IBC, etc), Celestia utilizes the default cosmos-sdk mechanisms for pricing resources. This involves incrementing a gas counter during transaction execution each time the state is read from/written to, or when specific costly operations occur such as signature verification or inclusion of data.
// GasMeter interface to track gas consumption
type GasMeter interface {
GasConsumed() Gas
GasConsumedToLimit() Gas
GasRemaining() Gas
Limit() Gas
ConsumeGas(amount Gas, descriptor string)
RefundGas(amount Gas, descriptor string)
IsPastLimit() bool
IsOutOfGas() bool
String() string
}
We can see how this gas meter is used in practice by looking at the store. Notice where gas is consumed each time we write or read, specifically a flat cost for initiating the action followed by a prorated cost for the amount of data read or written.
// Implements KVStore.
func (gs *Store) Get(key []byte) (value []byte) {
gs.gasMeter.ConsumeGas(gs.gasConfig.ReadCostFlat, types.GasReadCostFlatDesc)
value = gs.parent.Get(key)
// TODO overflow-safe math?
gs.gasMeter.ConsumeGas(gs.gasConfig.ReadCostPerByte*types.Gas(len(key)), types.GasReadPerByteDesc)
gs.gasMeter.ConsumeGas(gs.gasConfig.ReadCostPerByte*types.Gas(len(value)), types.GasReadPerByteDesc)
return value
}
// Implements KVStore.
func (gs *Store) Set(key []byte, value []byte) {
types.AssertValidKey(key)
types.AssertValidValue(value)
gs.gasMeter.ConsumeGas(gs.gasConfig.WriteCostFlat, types.GasWriteCostFlatDesc)
// TODO overflow-safe math?
gs.gasMeter.ConsumeGas(gs.gasConfig.WriteCostPerByte*types.Gas(len(key)), types.GasWritePerByteDesc)
gs.gasMeter.ConsumeGas(gs.gasConfig.WriteCostPerByte*types.Gas(len(value)), types.GasWritePerByteDesc)
gs.parent.Set(key, value)
}
The configuration for the gas meter used by Celestia is as follows.
// KVGasConfig returns a default gas config for KVStores.
func KVGasConfig() GasConfig {
return GasConfig{
HasCost: 1000,
DeleteCost: 1000,
ReadCostFlat: 1000,
ReadCostPerByte: 3,
WriteCostFlat: 2000,
WriteCostPerByte: 30,
IterNextCostFlat: 30,
}
}
// TransientGasConfig returns a default gas config for TransientStores.
func TransientGasConfig() GasConfig {
return GasConfig{
HasCost: 100,
DeleteCost: 100,
ReadCostFlat: 100,
ReadCostPerByte: 0,
WriteCostFlat: 200,
WriteCostPerByte: 3,
IterNextCostFlat: 3,
}
}
Two notable gas consumption events that are not Celestia specific are the total bytes used for a transaction and the verification of the signature
func (cgts ConsumeTxSizeGasDecorator) AnteHandle(ctx sdk.Context, tx sdk.Tx, simulate bool, next sdk.AnteHandler) (sdk.Context, error) {
sigTx, ok := tx.(authsigning.SigVerifiableTx)
if !ok {
return ctx, sdkerrors.Wrap(sdkerrors.ErrTxDecode, "invalid tx type")
}
params := cgts.ak.GetParams(ctx)
ctx.GasMeter().ConsumeGas(params.TxSizeCostPerByte*sdk.Gas(len(ctx.TxBytes())), "txSize")
...
}
// DefaultSigVerificationGasConsumer is the default implementation of SignatureVerificationGasConsumer. It consumes gas
// for signature verification based upon the public key type. The cost is fetched from the given params and is matched
// by the concrete type.
func DefaultSigVerificationGasConsumer(
meter sdk.GasMeter, sig signing.SignatureV2, params types.Params,
) error {
pubkey := sig.PubKey
switch pubkey := pubkey.(type) {
case *ed25519.PubKey:
meter.ConsumeGas(params.SigVerifyCostED25519, "ante verify: ed25519")
return sdkerrors.Wrap(sdkerrors.ErrInvalidPubKey, "ED25519 public keys are unsupported")
case *secp256k1.PubKey:
meter.ConsumeGas(params.SigVerifyCostSecp256k1, "ante verify: secp256k1")
return nil
case *secp256r1.PubKey:
meter.ConsumeGas(params.SigVerifyCostSecp256r1(), "ante verify: secp256r1")
return nil
case multisig.PubKey:
multisignature, ok := sig.Data.(*signing.MultiSignatureData)
if !ok {
return fmt.Errorf("expected %T, got, %T", &signing.MultiSignatureData{}, sig.Data)
}
err := ConsumeMultisignatureVerificationGas(meter, multisignature, pubkey, params, sig.Sequence)
if err != nil {
return err
}
return nil
default:
return sdkerrors.Wrapf(sdkerrors.ErrInvalidPubKey, "unrecognized public key type: %T", pubkey)
}
}
Since gas is consumed in this fashion and many of the cosmos-sdk transactions are composable, any given transaction can have a large window of possible gas consumption. For example, vesting accounts use more bytes of state than a normal account, so more gas is consumed each time a vesting account is read from or updated.
Parameters
There are four parameters that can be modified via governance to modify gas usage.
| Parameter | Default Value | Description | Changeable via Governance |
|---|---|---|---|
| consensus/max_gas | -1 | The maximum gas allowed in a block. Default of -1 means this value is not capped. | True |
| auth/tx_size_cost_per_byte | 10 | Gas used per each byte used by the transaction. | True |
| auth/sig_verify_cost_secp256k1 | 1000 | Gas used per verifying a secp256k1 signature | True |
| blob/gas_per_blob_byte | 8 | Gas used per byte used by blob. Note that this value is applied to all encoding overhead, meaning things like the padding of the remaining share and namespace. See PFB gas estimation section for more details. | True |
Gas Limit
The gas limit must be included in each transaction. If the transaction exceeds this gas limit during the execution of the transaction, then the transaction will fail.
Note: When a transaction is submitted to the mempool, the transaction is not fully executed. This can lead to a transaction getting accepted by the mempool and eventually included in a block, yet failing because the transaction ends up exceeding the gas limit.
Fees are not currently refunded. While users can specify a gas price, the total fee is then calculated by simply multiplying the gas limit by the gas price. The entire fee is then deducted from the transaction no matter what.
Fee market
By default, Celestia's consensus nodes prioritize transactions in their mempools
based on gas price. In version 1, there was no enforced minimum gas price, which
allowed each consensus node to independently set its own minimum gas price in
app.toml. This even permitted a gas price of 0, thereby creating the
possibility of secondary markets. In version 2, Celestia introduces a network
minimum gas price, a consensus constant, unaffected by individual node
configurations. Although nodes retain the freedom to increase gas prices
locally, all transactions in a block must be greater than or equal to the network
minimum threshold. If a block is proposed that contains a tx with a gas price
below the network min gas price, the block will be rejected as invalid.
Estimating PFB cost
Generally, the gas used by a PFB transaction involves a static "fixed cost" and a dynamic cost based on the size of each blob involved in the transaction.
Note: For a general use case of a normal account submitting a PFB, the static costs can be treated as such. However, due to the description above of how gas works in the cosmos-sdk this is not always the case. Notably, if we use a vesting account or the
feegrantmodules, then these static costs change.
The "fixed cost" is an approximation of the gas consumed by operations outside
the function GasToConsume (for example, signature verification, tx size, read
access to accounts), which has a default value of 65,000.
Note: the first transaction sent by an account (sequence number == 0) has an additional one time gas cost of 10,000. If this is the case, this should be accounted for.
Each blob in the PFB contributes to the total gas cost based on its size. The
function GasToConsume calculates the total gas consumed by all the blobs
involved in a PFB, where each blob's gas cost is computed by first determining
how many shares are needed to store the blob size. Then, it computes the product
of the number of shares, the number of bytes per share, and the gasPerByte
parameter. Finally, it adds a static amount per blob.
The gas cost per blob byte and gas cost per transaction byte are parameters that could potentially be adjusted through the system's governance mechanisms. Hence, actual costs may vary depending on the current settings of these parameters.
Tracing Gas Consumption
This figure plots each instance of the gas meter being incremented as a colored dot over the execution lifecycle of a given transaction. The y-axis is units of gas and the x-axis is cumulative gas consumption. The legend shows which color indicates what the cause of the gas consumption was.
This code used to trace gas consumption can be found in the tools/gasmonitor of the branch for #2131, and the script to generate the plots below can be found in this gist (warning: this script will not be maintained).
MsgSend
Here we can see the gas consumption trace of a common send transaction for
1utia
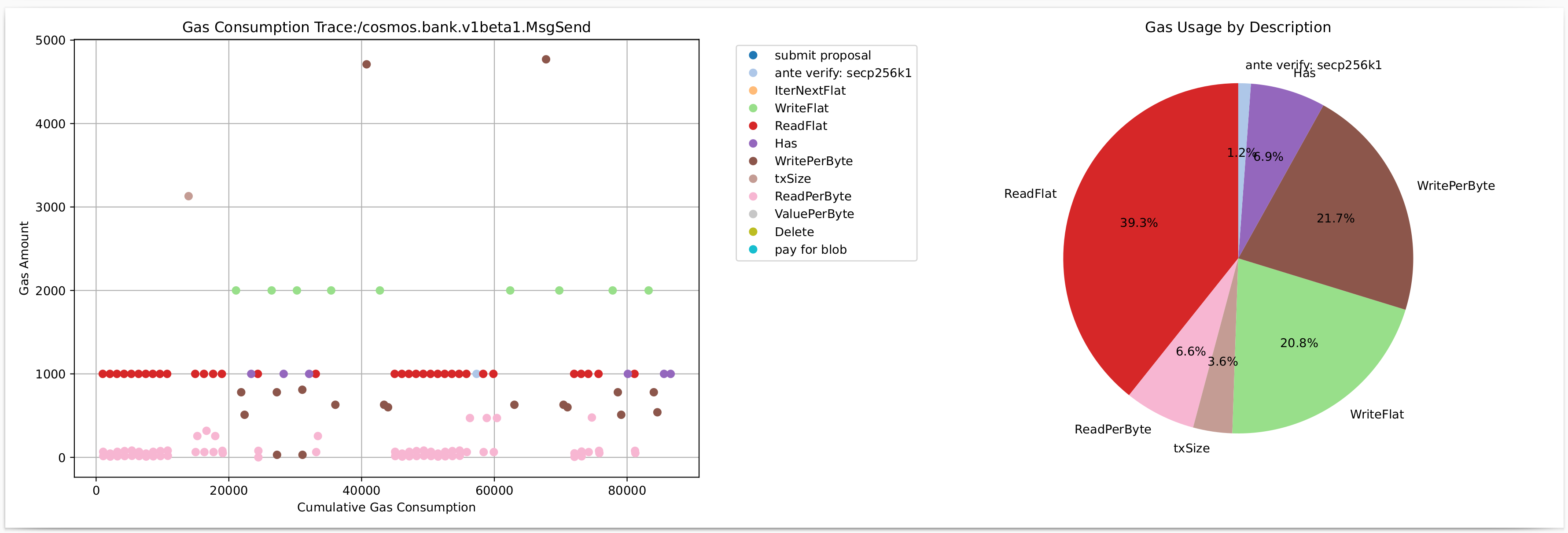
MsgCreateValidator
Here we examine a more complex transaction.
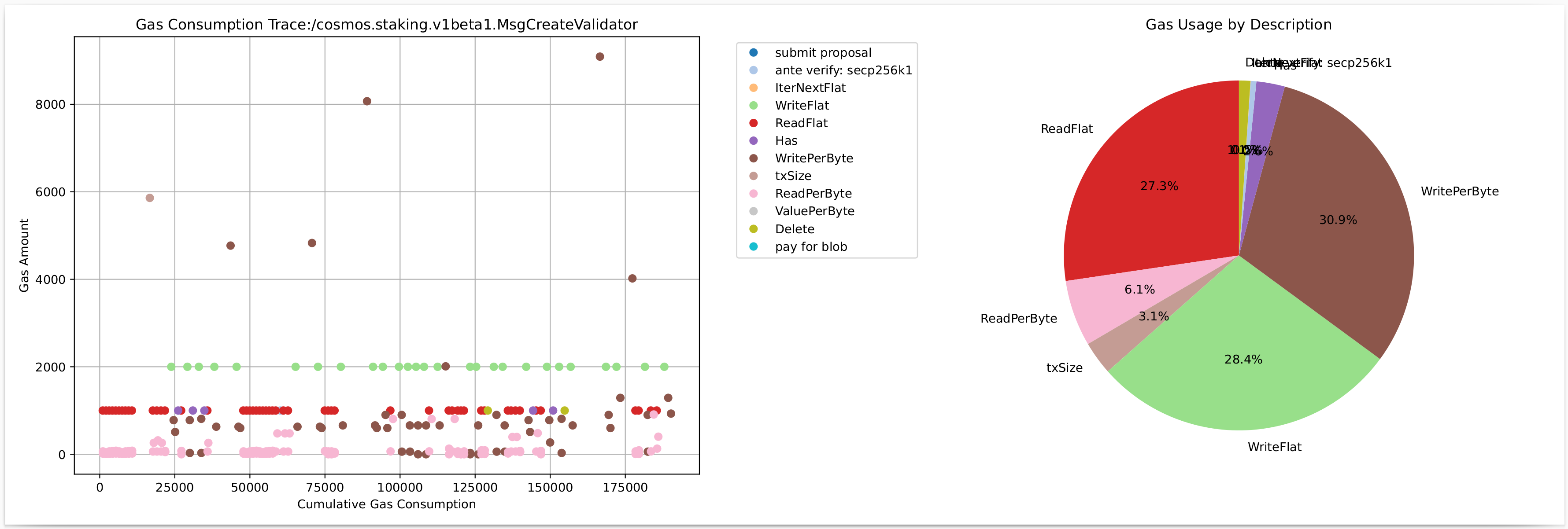
PFB with One Single Share Blob
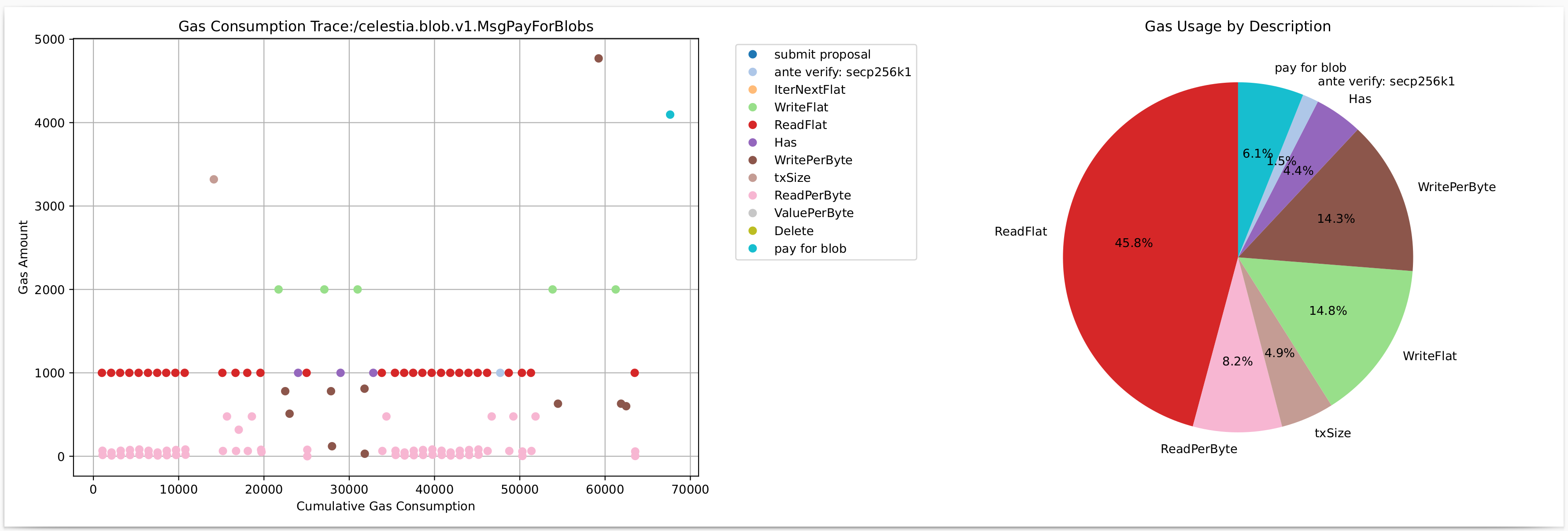
PFB with Two Single Share Blobs
This PFB transaction contains two single share blobs. Notice the gas cost for
pay for blob is double what it is above due to two shares being used, and
there is also additional cost from txSize since the transaction itself is
larger to accommodate the second set of metadata in the PFB.
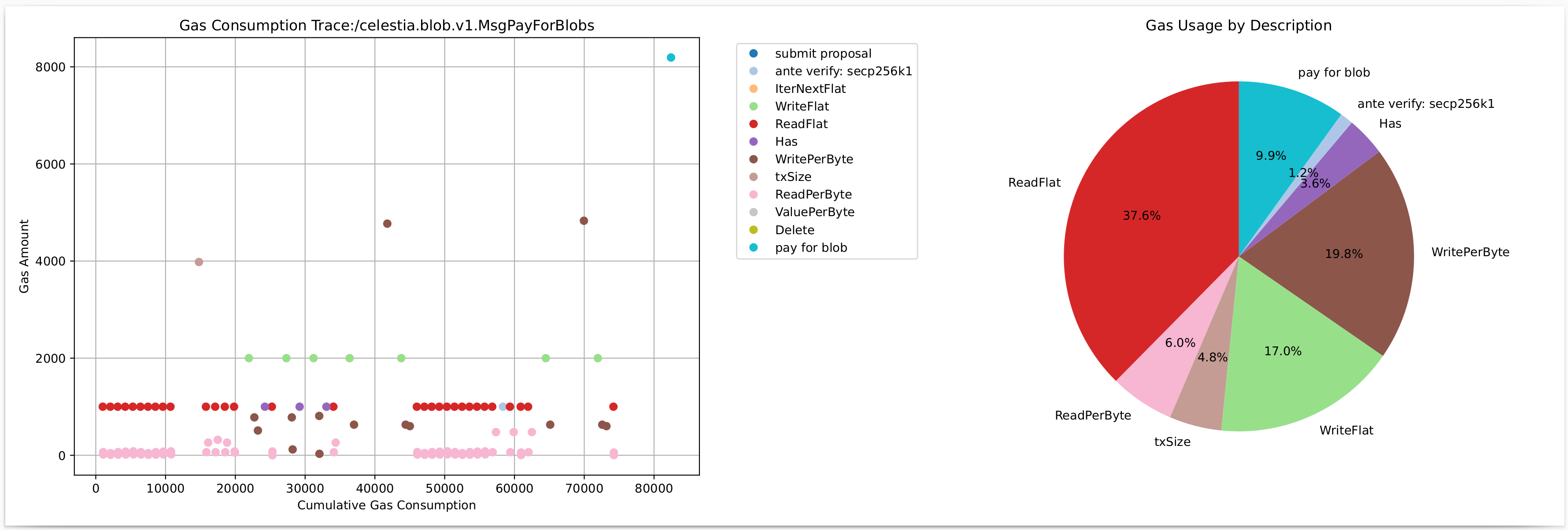
100KiB Single Blob PFB
Here we can see how the cost of a PFB with a large blob (100KiB) is quickly dominated by the cost of the blob.
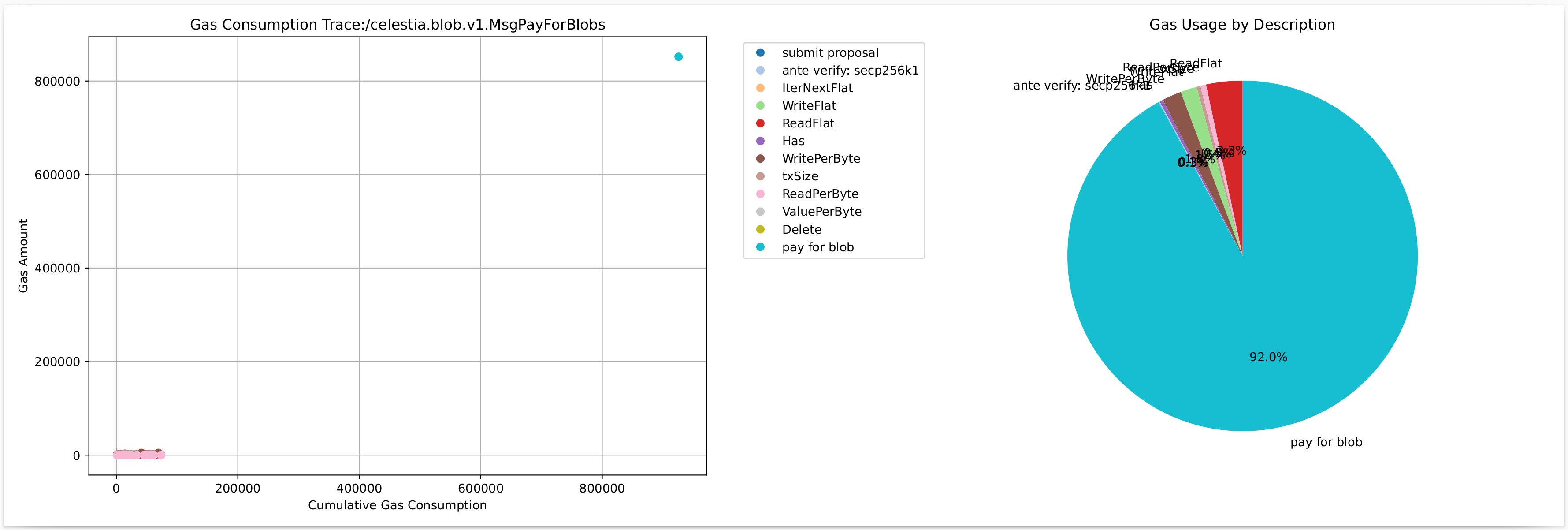
Multisig
Celestia inherits support for Multisig accounts from the Cosmos SDK. Multisig accounts behave similarly to regular accounts with the added requirement that a threshold of signatures is needed to authorize a transaction.
The maximum number of signatures allowed for a multisig account is determined by the parameter auth.TxSigLimit (see parameters). The threshold and list of signers for a multisig account are set at the time of creation and can be viewed in the pubkey field of a key. For example:
$ celestia-appd keys show multisig
- address: celestia17rehcgutjfra8zhjl8675t8hhw8wsavzzutv06
name: multisig
pubkey: '{"@type":"/cosmos.crypto.multisig.LegacyAminoPubKey","threshold":2,"public_keys":[{"@type":"/cosmos.crypto.secp256k1.PubKey","key":"AxMTEFDH8oyBPIH+d2MKfCIY1yAsEd0HVekoPaAOiu9c"},{"@type":"/cosmos.crypto.secp256k1.PubKey","key":"Ax0ANkTPWcCDWy9O2TcUXw90Z0DxnX2zqPvhi4VJPUl5"},{"@type":"/cosmos.crypto.secp256k1.PubKey","key":"AlUwWCGLzhclCMEKc2YLEap9H8JT5tWq1kB8BagU1TVH"}]}'
type: multi
Please see the Cosmos SDK docs for more information on how to use multisig accounts.
State Machine Modules
Celestia app is built using the cosmos-sdk, and follows standard cosmos-sdk module structure. The modules used in the application vary based on app version:
- State Machine Modules v1
- State Machine Modules v2
- State Machine Modules v3
- State Machine Modules v4
- State Machine Modules v5
- State Machine Modules v6
- State Machine Modules v7
- State Machine Modules v8
- State Machine Modules v9
- State Machine Modules v10
State Machine Modules v1
The modules used in app version 1 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- capability
- crisis
- distribution
- evidence
- feegrant
- genutil (no spec)
- gov
- params
- slashing
- staking
- vesting (no spec)
Third-party modules
State Machine Modules v2
The modules used in app version 2 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- capability
- crisis
- distribution
- evidence
- feegrant
- genutil (no spec)
- gov
- params
- slashing
- staking
- vesting (no spec)
Third-party modules
State Machine Modules v3
The modules used in app version 3 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- capability
- crisis
- distribution
- evidence
- feegrant
- genutil (no spec)
- gov
- params
- slashing
- staking
- vesting (no spec)
Third-party modules
State Machine Modules v4
The modules used in app version 4 are:
celestia-app modules
cosmos-sdk modules
Third-party modules
State Machine Modules v5
The modules used in app version 5 are:
celestia-app modules
cosmos-sdk modules
Third-party modules
State Machine Modules v6
The modules used in app version 6 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- circuit
- consensus
- distribution
- evidence
- feegrant
- genutil
- gov
- params
- slashing
- staking
- upgrade
- vesting
Third-party modules
State Machine Modules v7
The modules used in app version 7 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- circuit
- consensus
- distribution
- evidence
- feegrant
- genutil
- gov
- params
- slashing
- staking
- upgrade
- vesting
Third-party modules
State Machine Modules v8
The modules used in app version 8 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- circuit
- consensus
- distribution
- evidence
- feegrant
- genutil
- gov
- params
- slashing
- staking
- upgrade
- vesting
Third-party modules
State Machine Modules v9
The modules used in app version 9 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- circuit
- consensus
- distribution
- evidence
- feegrant
- genutil
- gov
- params
- slashing
- staking
- upgrade
- vesting
Third-party modules
State Machine Modules v10
The modules used in app version 10 are:
celestia-app modules
cosmos-sdk modules
- auth
- authz
- bank
- circuit
- consensus
- distribution
- evidence
- feegrant
- genutil
- gov
- params
- slashing
- staking
- upgrade
- vesting
Third-party modules
Parameters
The parameters in the application depend on the app version:
- Parameters v1
- Parameters v2
- Parameters v3
- Parameters v4
- Parameters v5
- Parameters v6
- Parameters v7
- Parameters v8
- Parameters v9
- Parameters v10
Parameters v1
The parameters below represent the parameters for app version 1.
Note that not all of these parameters are changeable via governance. This list
also includes parameters that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the x/paramfilter module.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 128 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxBlockSizeBytes | 100 MiB | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | True |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | True |
| blob.GovMaxSquareSize | 64 | Governance parameter for the maximum square size determined per shares per row or column for the original data square (not yet extended). If larger than MaxSquareSize, MaxSquareSize is used. | True |
| blobstream.DataCommitmentWindow | 400 | Number of blocks that are included in a signed batch (DataCommitment). | True |
| consensus.block.MaxBytes | 1974272 bytes (~1.88 MiB) | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 1814400000000000 (21 days) | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 120960 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 1 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.DepositParams.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.DepositParams.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.TallyParams.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.TallyParams.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.TallyParams.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingParams.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.10 (10%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.08 (8%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 5000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.05 (5%) | Minimum commission rate used by all validators. | True |
| staking.UnbondingTime | 1814400 (21 days) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v2
The parameters below represent the parameters for app version 2.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the x/paramfilter module.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 128 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| UpgradeHeightDelay | 50400 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 100 MiB | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | True |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | True |
| blob.GovMaxSquareSize | 64 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 1974272 bytes (~1.88 MiB) | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 1814400000000000 (21 days) | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 120960 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 2 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.DepositParams.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.DepositParams.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.TallyParams.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.TallyParams.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.TallyParams.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingParams.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.10 (10%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.08 (8%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 5000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.05 (5%) | Minimum commission rate used by all validators. | True |
| staking.UnbondingTime | 1814400 (21 days) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v3
The parameters below represent the parameters for app version 3.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the x/paramfilter module.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 128 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 2 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 3500 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutCommit | 4200 ms | Specifies the duration that validators wait during the Commit phase of the consensus process. See CometBFT specs for more details. | False |
| UpgradeHeightDelay | 100800 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 100 MiB | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 64 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 1974272 bytes (~1.88 MiB) | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 1814400000000000 (21 days) | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 120960 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 3 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.DepositParams.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.DepositParams.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.TallyParams.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.TallyParams.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.TallyParams.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingParams.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.10 (10%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.08 (8%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 5000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.05 (5%) | Minimum commission rate used by all validators. | True |
| staking.UnbondingTime | 1814400 (21 days) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v4
The parameters below represent the parameters for app version 4.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 128 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 2 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 3500 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutCommit | 4200 ms | Specifies the duration that validators wait during the Commit phase of the consensus process. See CometBFT specs for more details. | False |
| UpgradeHeightDelay | 100800 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 100 MiB | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 64 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 1974272 bytes (~1.88 MiB) | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 1814400000000000 (21 days) | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 120960 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 4 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0536 (5.36%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 5000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.05 (5%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.25 (25%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1814400 (21 days) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v5
The parameters below represent the parameters for app version 5.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 128 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 2 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 3500 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutCommit | 4200 ms | Specifies the duration that validators wait during the Commit phase of the consensus process. See CometBFT specs for more details. | False |
| UpgradeHeightDelay | 100800 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 100 MiB | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 256 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 1974272 bytes (~1.88 MiB) | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 1814400000000000 (21 days) | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 120960 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 5 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0536 (5.36%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 5000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.05 (5%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.25 (25%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1814400 (21 days) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v6
The parameters below represent the parameters for app version 6.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 512 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 8 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 8500 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutProposeDelta | 500 ms | Increase in the proposal timeout for each additional round of consensus. | False |
| TimeoutPrevote | 3000 ms | Specifies the time that validators wait for a prevote to be received. See CometBFT specs for more details. | False |
| TimeoutPrevoteDelta | 500 ms | Increase in the prevote timeout for each additional round of consensus. | False |
| TimeoutPrecommit | 3000 ms | Specifies the time that validators wait for a precommit to be received. See CometBFT specs for more details. | False |
| TimeoutPrecommitDelta | 500 ms | Increase in the precommit timeout for each additional round of consensus. | False |
| TimeoutCommit | 1 ms | Specifies the duration that validators wait after committing a block before starting on the new height. See CometBFT specs for more details. | False |
| DelayedPrecommitTimeout | 5850 ms | Time after a delayed precommit before the node proceeds to the next step. | False |
| UpgradeHeightDelay | 100800 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 130857600 bytes | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 256 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 32 MiB | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 337 hours | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 242,640 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1 MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 6 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0267 (2.67%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 10000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.10 (10%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.25 (25%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1814400 (21 days) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v7
The parameters below represent the parameters for app version 7.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 512 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 8 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 8500 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutProposeDelta | 500 ms | Increase in the proposal timeout for each additional round of consensus. | False |
| TimeoutPrevote | 3000 ms | Specifies the time that validators wait for a prevote to be received. See CometBFT specs for more details. | False |
| TimeoutPrevoteDelta | 500 ms | Increase in the prevote timeout for each additional round of consensus. | False |
| TimeoutPrecommit | 3000 ms | Specifies the time that validators wait for a precommit to be received. See CometBFT specs for more details. | False |
| TimeoutPrecommitDelta | 500 ms | Increase in the precommit timeout for each additional round of consensus. | False |
| TimeoutCommit | 1 ms | Specifies the duration that validators wait after committing a block before starting on the new height. See CometBFT specs for more details. | False |
| DelayedPrecommitTimeout | 5850 ms | Time after a delayed precommit before the node proceeds to the next step. | False |
| UpgradeHeightDelay | 100800 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 130857600 bytes | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 256 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 32 MiB | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 337 hours | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 242,640 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1 MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 7 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0267 (2.67%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 10000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.20 (20%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.60 (60%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1213200 (337 hours) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v8
The parameters below represent the parameters for app version 8.
Note that not all of these parameters are changeable via governance. This list
also includes parameter that require a hardfork to change due to being manually
hardcoded in the application or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 512 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 8 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 8500 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutProposeDelta | 500 ms | Increase in the proposal timeout for each additional round of consensus. | False |
| TimeoutPrevote | 3000 ms | Specifies the time that validators wait for a prevote to be received. See CometBFT specs for more details. | False |
| TimeoutPrevoteDelta | 500 ms | Increase in the prevote timeout for each additional round of consensus. | False |
| TimeoutPrecommit | 3000 ms | Specifies the time that validators wait for a precommit to be received. See CometBFT specs for more details. | False |
| TimeoutPrecommitDelta | 500 ms | Increase in the precommit timeout for each additional round of consensus. | False |
| TimeoutCommit | 1 ms | Specifies the duration that validators wait after committing a block before starting on the new height. See CometBFT specs for more details. | False |
| DelayedPrecommitTimeout | 5850 ms | Time after a delayed precommit before the node proceeds to the next step. | False |
| UpgradeHeightDelay | 100800 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 130857600 bytes | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 256 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 128 MiB | Governance parameter for the maximum size of the protobuf encoded block. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 337 hours | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 242,640 | The maximum number of blocks before evidence is considered invalid. This value will stop CometBFT from pruning block data. | True |
| consensus.evidence.MaxBytes | 1 MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 8 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 75000000000 (75 seconds) | Maximum expected time per block in nanoseconds under normal operation. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0267 (2.67%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 10000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.20 (20%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.60 (60%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1213200 (337 hours) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v9
The parameters below represent the parameters for app version 9.
Note that not all of these parameters are changeable via governance. This list
also includes parameters that require a hardfork to change due to being manually
hardcoded in the application, or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 512 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 8 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 3000 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutProposeDelta | 500 ms | Increase in the proposal timeout for each additional round of consensus. | False |
| TimeoutPrevote | 2000 ms | Specifies the time that validators wait for a prevote to be received. See CometBFT specs for more details. | False |
| TimeoutPrevoteDelta | 500 ms | Increase in the prevote timeout for each additional round of consensus. | False |
| TimeoutPrecommit | 3000 ms | Specifies the time that validators wait for a precommit to be received. See CometBFT specs for more details. | False |
| TimeoutPrecommitDelta | 500 ms | Increase in the precommit timeout for each additional round of consensus. | False |
| TimeoutCommit | 500 ms | Specifies the duration that validators wait after committing a block before starting on the new height. See CometBFT specs for more details. | False |
| DelayedPrecommitTimeout | 2100 ms | Time after a delayed precommit before the node proceeds to the next step. | False |
| UpgradeHeightDelay | 232616 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 130857600 bytes | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 256 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 32 MiB | Governance parameter for the maximum size of the protobuf encoded block. Set via the v9 upgrade handler. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 337 hours | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 559,940 | The maximum number of blocks before evidence is considered invalid. Scaled from 242,640 to preserve ~16.85 days at ~2.6s block times. See CIP-048. | True |
| consensus.evidence.MaxBytes | 1 MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 9 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 13000000000 (13 seconds) | Maximum expected time per block in nanoseconds under normal operation. Set via the v9 upgrade handler. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0267 (2.67%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 10000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.20 (20%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.60 (60%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1213200 (337 hours) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Parameters v10
The parameters below represent the parameters for app version 10.
Note that not all of these parameters are changeable via governance. This list
also includes parameters that require a hardfork to change due to being manually
hardcoded in the application, or they are blocked by the ParamFilterDecorator.
Parameters that are governance modifiables can be modified via a
MsgSubmitProposal that contains a moduleXYZ.MsgUpdateParams message.
Global parameters
| Parameter | Value | Summary | Changeable via Governance |
|---|---|---|---|
| SquareSizeUpperBound | 512 | Hardcoded maximum square size which limits the number of shares per row or column for the original data square (not yet extended). | False |
| SubtreeRootThreshold | 64 | See ADR-013 for more details. | False |
| MaxTxSize | 8 MiB | Maximum size of a transaction in bytes. | False |
| TimeoutPropose | 3000 ms | Specifies the time that validators wait during the proposal phase of the consensus process. See CometBFT specs for more details. | False |
| TimeoutProposeDelta | 500 ms | Increase in the proposal timeout for each additional round of consensus. | False |
| TimeoutPrevote | 2000 ms | Specifies the time that validators wait for a prevote to be received. See CometBFT specs for more details. | False |
| TimeoutPrevoteDelta | 500 ms | Increase in the prevote timeout for each additional round of consensus. | False |
| TimeoutPrecommit | 3000 ms | Specifies the time that validators wait for a precommit to be received. See CometBFT specs for more details. | False |
| TimeoutPrecommitDelta | 500 ms | Increase in the precommit timeout for each additional round of consensus. | False |
| TimeoutCommit | 500 ms | Specifies the duration that validators wait after committing a block before starting on the new height. See CometBFT specs for more details. | False |
| DelayedPrecommitTimeout | 2100 ms | Time after a delayed precommit before the node proceeds to the next step. | False |
| UpgradeHeightDelay | 232616 blocks | Height based delay after a successful MsgTryUpgrade has been submitted. | False |
| MaxBlockSizeBytes | 130857600 bytes | Hardcoded value in CometBFT for the protobuf encoded block. | False |
Module parameters
| Module.Parameter | Default | Summary | Changeable via Governance |
|---|---|---|---|
| auth.MaxMemoCharacters | 256 | Largest allowed size for a memo in bytes. | True |
| auth.SigVerifyCostED25519 | 590 | Gas used to verify Ed25519 signature. | True |
| auth.SigVerifyCostSecp256k1 | 1000 | Gas used to verify secp256k1 signature. | True |
| auth.TxSigLimit | 7 | Max number of signatures allowed in a multisig transaction. | True |
| auth.TxSizeCostPerByte | 10 | Gas used per transaction byte. | False |
| bank.SendEnabled | true | Allow transfers. | False |
| blob.GasPerBlobByte | 8 | Gas used per blob byte. | False |
| blob.GovMaxSquareSize | 256 | Governance parameter for the maximum square size of the original data square. | True |
| consensus.block.MaxBytes | 32 MiB | Governance parameter for the maximum size of the protobuf encoded block. Set via the v9 upgrade handler. | True |
| consensus.block.MaxGas | -1 | Maximum gas allowed per block (-1 is infinite). | True |
| consensus.block.TimeIotaMs | 1000 | Minimum time added to the time in the header each block. | False |
| consensus.evidence.MaxAgeDuration | 337 hours | The maximum age of evidence before it is considered invalid in nanoseconds. This value should be identical to the unbonding period. | True |
| consensus.evidence.MaxAgeNumBlocks | 559,940 | The maximum number of blocks before evidence is considered invalid. Scaled from 242,640 to preserve ~16.85 days at ~2.6s block times. See CIP-048. | True |
| consensus.evidence.MaxBytes | 1 MiB | Maximum size in bytes used by evidence in a given block. | True |
| consensus.validator.PubKeyTypes | Ed25519 | The type of public key used by validators. | False |
| consensus.Version.AppVersion | 10 | Determines protocol rules used for a given height. Incremented by the application upon an upgrade. | True |
| distribution.BaseProposerReward | 0 | Reward in the mint denomination for proposing a block. | True |
| distribution.BonusProposerReward | 0 | Extra reward in the mint denomination for proposers based on the voting power included in the commit. | True |
| distribution.CommunityTax | 0.02 (2%) | Percentage of the inflation sent to the community pool. | True |
| distribution.WithdrawAddrEnabled | true | Enables delegators to withdraw funds to a different address. | True |
| gov.MaxDepositPeriod | 604800000000000 (1 week) | Maximum period for token holders to deposit on a proposal in nanoseconds. | True |
| gov.MinDeposit | 10_000_000_000 utia (10,000 TIA) | Minimum deposit for a proposal to enter voting period. | True |
| gov.Quorum | 0.334 (33.4%) | Minimum percentage of total stake needed to vote for a result to be considered valid. | True |
| gov.Threshold | 0.50 (50%) | Minimum proportion of Yes votes for proposal to pass. | True |
| gov.VetoThreshold | 0.334 (33.4%) | Minimum value of Veto votes to Total votes ratio for proposal to be vetoed. | True |
| gov.VotingPeriod | 604800000000000 (1 week) | Duration of the voting period in nanoseconds. | True |
| gov.ExpeditedMinDeposit | 50_000_000_000 utia (50,000 TIA) | Minimum deposit for an expedited proposal. | True |
| gov.ExpeditedVotingPeriod | 86400000000000 (1 day) | Duration of the expedited voting period in nanoseconds. | True |
| gov.ExpeditedThreshold | 0.667 (66.7%) | Minimum proportion of Yes votes for an expedited proposal to pass. | True |
| ibc.ClientGenesis.AllowedClients | []string{"06-solomachine", "07-tendermint"} | List of allowed IBC light clients. | True |
| ibc.ConnectionGenesis.MaxExpectedTimePerBlock | 13000000000 (13 seconds) | Maximum expected time per block in nanoseconds under normal operation. Set via the v9 upgrade handler. | True |
| ibc.Transfer.ReceiveEnabled | true | Enable receiving tokens via IBC. | True |
| ibc.Transfer.SendEnabled | true | Enable sending tokens via IBC. | True |
| icahost.HostEnabled | True | Enables or disables the Inter-Chain Accounts host module. | True |
| icahost.AllowMessages | icaAllowMessages | Defines a list of sdk message typeURLs allowed to be executed on a host chain. | True |
| minfee.NetworkMinGasPrice | 0.000001 utia | All transactions must have a gas price greater than or equal to this value. | True |
| mint.BondDenom | utia | Denomination that is inflated and sent to the distribution module account. | False |
| mint.DisinflationRate | 0.067 (6.7%) | The rate at which the inflation rate decreases each year. | False |
| mint.InitialInflationRate | 0.0267 (2.67%) | The inflation rate the network starts at. | False |
| mint.TargetInflationRate | 0.015 (1.5%) | The inflation rate that the network aims to stabilize at. | False |
| packetforwardmiddleware.FeePercentage | 0 | % of the forwarded packet amount which will be subtracted and distributed to the community pool. | True |
| slashing.DowntimeJailDuration | 1 min | Duration of time a validator must stay jailed. | True |
| slashing.MinSignedPerWindow | 0.75 (75%) | The percentage of SignedBlocksWindow that must be signed not to get jailed. | True |
| slashing.SignedBlocksWindow | 10000 | The range of blocks used to count for downtime. | True |
| slashing.SlashFractionDoubleSign | 0.02 (2%) | Percentage slashed after a validator is jailed for double signing. | True |
| slashing.SlashFractionDowntime | 0.00 (0%) | Percentage slashed after a validator is jailed for downtime. | True |
| staking.BondDenom | utia | Bondable coin denomination. | False |
| staking.HistoricalEntries | 10000 | Number of historical entries to persist in store. | True |
| staking.MaxEntries | 7 | Maximum number of entries in the redelegation queue. | True |
| staking.MaxValidators | 100 | Maximum number of validators. | True |
| staking.MinCommissionRate | 0.20 (20%) | Minimum commission rate used by all validators. | True |
| staking.MaxCommissionRate | 0.60 (60%) | Maximum commission rate that validators can set when creating or updating their commission. | False |
| staking.UnbondingTime | 1213200 (337 hours) | Duration of time for unbonding in seconds. | False |
Note: none of the mint module parameters are governance modifiable because they have been converted into hardcoded constants. See the x/mint README.md for more details.
Types
The following pages contain the types used by celestia-app. The target audience of these pages is block explorers and other tools that need an exhaustive list of supporrted Cosmos SDK Msg types and events.
Types v5
Msgs
The following is an exhaustive list of supported Cosmos SDK Msgs for app version 5.
/celestia.blob.v1.MsgPayForBlobs
/celestia.blob.v1.MsgUpdateBlobParams
/celestia.minfee.v1.MsgUpdateMinfeeParams
/celestia.signal.v1.MsgSignalVersion
/celestia.signal.v1.MsgTryUpgrade
/cosmos.auth.v1beta1.MsgUpdateParams
/cosmos.authz.v1beta1.MsgExec
/cosmos.authz.v1beta1.MsgGrant
/cosmos.authz.v1beta1.MsgPruneExpiredGrants
/cosmos.authz.v1beta1.MsgRevoke
/cosmos.bank.v1beta1.MsgMultiSend
/cosmos.bank.v1beta1.MsgSend
/cosmos.bank.v1beta1.MsgSetSendEnabled
/cosmos.bank.v1beta1.MsgUpdateParams
/cosmos.circuit.v1.MsgAuthorizeCircuitBreaker
/cosmos.circuit.v1.MsgResetCircuitBreaker
/cosmos.circuit.v1.MsgTripCircuitBreaker
/cosmos.consensus.v1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgCommunityPoolSpend
/cosmos.distribution.v1beta1.MsgDepositValidatorRewardsPool
/cosmos.distribution.v1beta1.MsgFundCommunityPool
/cosmos.distribution.v1beta1.MsgSetWithdrawAddress
/cosmos.distribution.v1beta1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgWithdrawDelegatorReward
/cosmos.distribution.v1beta1.MsgWithdrawValidatorCommission
/cosmos.evidence.v1beta1.MsgSubmitEvidence
/cosmos.feegrant.v1beta1.MsgGrantAllowance
/cosmos.feegrant.v1beta1.MsgPruneAllowances
/cosmos.feegrant.v1beta1.MsgRevokeAllowance
/cosmos.gov.v1.MsgCancelProposal
/cosmos.gov.v1.MsgDeposit
/cosmos.gov.v1.MsgExecLegacyContent
/cosmos.gov.v1.MsgSubmitProposal
/cosmos.gov.v1.MsgUpdateParams
/cosmos.gov.v1.MsgVote
/cosmos.gov.v1.MsgVoteWeighted
/cosmos.gov.v1beta1.MsgDeposit
/cosmos.gov.v1beta1.MsgSubmitProposal
/cosmos.gov.v1beta1.MsgVote
/cosmos.gov.v1beta1.MsgVoteWeighted
/cosmos.slashing.v1beta1.MsgUnjail
/cosmos.slashing.v1beta1.MsgUpdateParams
/cosmos.staking.v1beta1.MsgBeginRedelegate
/cosmos.staking.v1beta1.MsgCancelUnbondingDelegation
/cosmos.staking.v1beta1.MsgCreateValidator
/cosmos.staking.v1beta1.MsgDelegate
/cosmos.staking.v1beta1.MsgEditValidator
/cosmos.staking.v1beta1.MsgUndelegate
/cosmos.staking.v1beta1.MsgUpdateParams
/cosmos.upgrade.v1beta1.MsgCancelUpgrade
/cosmos.upgrade.v1beta1.MsgSoftwareUpgrade
/cosmos.vesting.v1beta1.MsgCreatePeriodicVestingAccount
/cosmos.vesting.v1beta1.MsgCreatePermanentLockedAccount
/cosmos.vesting.v1beta1.MsgCreateVestingAccount
/hyperlane.core.interchain_security.v1.MsgAnnounceValidator
/hyperlane.core.interchain_security.v1.MsgCreateMerkleRootMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateMessageIdMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateNoopIsm
/hyperlane.core.interchain_security.v1.MsgCreateRoutingIsm
/hyperlane.core.interchain_security.v1.MsgRemoveRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgSetRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgUpdateRoutingIsmOwner
/hyperlane.core.post_dispatch.v1.MsgClaim
/hyperlane.core.post_dispatch.v1.MsgCreateIgp
/hyperlane.core.post_dispatch.v1.MsgCreateMerkleTreeHook
/hyperlane.core.post_dispatch.v1.MsgCreateNoopHook
/hyperlane.core.post_dispatch.v1.MsgPayForGas
/hyperlane.core.post_dispatch.v1.MsgSetDestinationGasConfig
/hyperlane.core.post_dispatch.v1.MsgSetIgpOwner
/hyperlane.core.v1.MsgCreateMailbox
/hyperlane.core.v1.MsgProcessMessage
/hyperlane.core.v1.MsgSetMailbox
/hyperlane.warp.v1.MsgCreateCollateralToken
/hyperlane.warp.v1.MsgCreateSyntheticToken
/hyperlane.warp.v1.MsgEnrollRemoteRouter
/hyperlane.warp.v1.MsgRemoteTransfer
/hyperlane.warp.v1.MsgSetToken
/hyperlane.warp.v1.MsgSetTokenResponse
/hyperlane.warp.v1.MsgUnrollRemoteRouter
/ibc.applications.interchain_accounts.controller.v1.MsgRegisterInterchainAccount
/ibc.applications.interchain_accounts.controller.v1.MsgSendTx
/ibc.applications.interchain_accounts.controller.v1.MsgUpdateParams
/ibc.applications.interchain_accounts.host.v1.MsgModuleQuerySafe
/ibc.applications.interchain_accounts.host.v1.MsgUpdateParams
/ibc.applications.transfer.v1.MsgTransfer
/ibc.applications.transfer.v1.MsgUpdateParams
/ibc.core.channel.v1.MsgAcknowledgement
/ibc.core.channel.v1.MsgChannelCloseConfirm
/ibc.core.channel.v1.MsgChannelCloseInit
/ibc.core.channel.v1.MsgChannelOpenAck
/ibc.core.channel.v1.MsgChannelOpenConfirm
/ibc.core.channel.v1.MsgChannelOpenInit
/ibc.core.channel.v1.MsgChannelOpenTry
/ibc.core.channel.v1.MsgChannelUpgradeAck
/ibc.core.channel.v1.MsgChannelUpgradeCancel
/ibc.core.channel.v1.MsgChannelUpgradeConfirm
/ibc.core.channel.v1.MsgChannelUpgradeInit
/ibc.core.channel.v1.MsgChannelUpgradeOpen
/ibc.core.channel.v1.MsgChannelUpgradeTimeout
/ibc.core.channel.v1.MsgChannelUpgradeTry
/ibc.core.channel.v1.MsgPruneAcknowledgements
/ibc.core.channel.v1.MsgRecvPacket
/ibc.core.channel.v1.MsgTimeout
/ibc.core.channel.v1.MsgTimeoutOnClose
/ibc.core.channel.v1.MsgUpdateParams
/ibc.core.client.v1.MsgCreateClient
/ibc.core.client.v1.MsgIBCSoftwareUpgrade
/ibc.core.client.v1.MsgRecoverClient
/ibc.core.client.v1.MsgSubmitMisbehaviour
/ibc.core.client.v1.MsgUpdateClient
/ibc.core.client.v1.MsgUpdateParams
/ibc.core.client.v1.MsgUpgradeClient
/ibc.core.connection.v1.MsgConnectionOpenAck
/ibc.core.connection.v1.MsgConnectionOpenConfirm
/ibc.core.connection.v1.MsgConnectionOpenInit
/ibc.core.connection.v1.MsgConnectionOpenTry
/ibc.core.connection.v1.MsgUpdateParams
Events
The following is an exhaustive list of supported events for app version 5.
celestia.blob.v1.EventPayForBlobs
celestia.blob.v1.EventUpdateBlobParams
celestia.minfee.v1.EventUpdateMinfeeParams
cosmos.authz.v1beta1.EventGrant
cosmos.authz.v1beta1.EventPruneExpiredGrants
cosmos.authz.v1beta1.EventRevoke
cosmos.base.abci.v1beta1.StringEvent
cosmos.distribution.v1beta1.ValidatorSlashEvent
cosmos.distribution.v1beta1.ValidatorSlashEventRecord
cosmos.distribution.v1beta1.ValidatorSlashEvents
cosmos.group.v1.EventCreateGroup
cosmos.group.v1.EventCreateGroupPolicy
cosmos.group.v1.EventExec
cosmos.group.v1.EventLeaveGroup
cosmos.group.v1.EventProposalPruned
cosmos.group.v1.EventSubmitProposal
cosmos.group.v1.EventTallyError
cosmos.group.v1.EventUpdateGroup
cosmos.group.v1.EventUpdateGroupPolicy
cosmos.group.v1.EventVote
cosmos.group.v1.EventWithdrawProposal
cosmos.tx.v1beta1.GetTxsEventRequest
cosmos.tx.v1beta1.GetTxsEventResponse
envoy.config.core.v3.EventServiceConfig
hyperlane.core.interchain_security.v1.EventAnnounceStorageLocation
hyperlane.core.interchain_security.v1.EventCreateMerkleRootMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateMessageIdMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateNoopIsm
hyperlane.core.interchain_security.v1.EventCreateRoutingIsm
hyperlane.core.interchain_security.v1.EventRemoveRoutingIsmDomain
hyperlane.core.interchain_security.v1.EventSetRoutingIsm
hyperlane.core.interchain_security.v1.EventSetRoutingIsmDomain
hyperlane.core.post_dispatch.v1.EventClaimIgp
hyperlane.core.post_dispatch.v1.EventCreateIgp
hyperlane.core.post_dispatch.v1.EventCreateMerkleTreeHook
hyperlane.core.post_dispatch.v1.EventCreateNoopHook
hyperlane.core.post_dispatch.v1.EventGasPayment
hyperlane.core.post_dispatch.v1.EventInsertedIntoTree
hyperlane.core.post_dispatch.v1.EventSetDestinationGasConfig
hyperlane.core.post_dispatch.v1.EventSetIgp
hyperlane.core.v1.EventCreateMailbox
hyperlane.core.v1.EventDispatch
hyperlane.core.v1.EventProcess
hyperlane.core.v1.EventSetMailbox
hyperlane.warp.v1.EventCreateCollateralToken
hyperlane.warp.v1.EventCreateSyntheticToken
hyperlane.warp.v1.EventEnrollRemoteRouter
hyperlane.warp.v1.EventReceiveRemoteTransfer
hyperlane.warp.v1.EventSendRemoteTransfer
hyperlane.warp.v1.EventSetToken
hyperlane.warp.v1.EventUnrollRemoteRouter
Types v6
Msgs
The following is an exhaustive list of supported Cosmos SDK Msgs for app version 6.
/celestia.blob.v1.MsgPayForBlobs
/celestia.blob.v1.MsgUpdateBlobParams
/celestia.minfee.v1.MsgUpdateMinfeeParams
/celestia.signal.v1.MsgSignalVersion
/celestia.signal.v1.MsgTryUpgrade
/cosmos.auth.v1beta1.MsgUpdateParams
/cosmos.authz.v1beta1.MsgExec
/cosmos.authz.v1beta1.MsgGrant
/cosmos.authz.v1beta1.MsgPruneExpiredGrants
/cosmos.authz.v1beta1.MsgRevoke
/cosmos.bank.v1beta1.MsgMultiSend
/cosmos.bank.v1beta1.MsgSend
/cosmos.bank.v1beta1.MsgSetSendEnabled
/cosmos.bank.v1beta1.MsgUpdateParams
/cosmos.circuit.v1.MsgAuthorizeCircuitBreaker
/cosmos.circuit.v1.MsgResetCircuitBreaker
/cosmos.circuit.v1.MsgTripCircuitBreaker
/cosmos.consensus.v1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgCommunityPoolSpend
/cosmos.distribution.v1beta1.MsgDepositValidatorRewardsPool
/cosmos.distribution.v1beta1.MsgFundCommunityPool
/cosmos.distribution.v1beta1.MsgSetWithdrawAddress
/cosmos.distribution.v1beta1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgWithdrawDelegatorReward
/cosmos.distribution.v1beta1.MsgWithdrawValidatorCommission
/cosmos.evidence.v1beta1.MsgSubmitEvidence
/cosmos.feegrant.v1beta1.MsgGrantAllowance
/cosmos.feegrant.v1beta1.MsgPruneAllowances
/cosmos.feegrant.v1beta1.MsgRevokeAllowance
/cosmos.gov.v1.MsgCancelProposal
/cosmos.gov.v1.MsgDeposit
/cosmos.gov.v1.MsgExecLegacyContent
/cosmos.gov.v1.MsgSubmitProposal
/cosmos.gov.v1.MsgUpdateParams
/cosmos.gov.v1.MsgVote
/cosmos.gov.v1.MsgVoteWeighted
/cosmos.gov.v1beta1.MsgDeposit
/cosmos.gov.v1beta1.MsgSubmitProposal
/cosmos.gov.v1beta1.MsgVote
/cosmos.gov.v1beta1.MsgVoteWeighted
/cosmos.slashing.v1beta1.MsgUnjail
/cosmos.slashing.v1beta1.MsgUpdateParams
/cosmos.staking.v1beta1.MsgBeginRedelegate
/cosmos.staking.v1beta1.MsgCancelUnbondingDelegation
/cosmos.staking.v1beta1.MsgCreateValidator
/cosmos.staking.v1beta1.MsgDelegate
/cosmos.staking.v1beta1.MsgEditValidator
/cosmos.staking.v1beta1.MsgUndelegate
/cosmos.staking.v1beta1.MsgUpdateParams
/cosmos.upgrade.v1beta1.MsgCancelUpgrade
/cosmos.upgrade.v1beta1.MsgSoftwareUpgrade
/cosmos.vesting.v1beta1.MsgCreatePeriodicVestingAccount
/cosmos.vesting.v1beta1.MsgCreatePermanentLockedAccount
/cosmos.vesting.v1beta1.MsgCreateVestingAccount
/hyperlane.core.interchain_security.v1.MsgAnnounceValidator
/hyperlane.core.interchain_security.v1.MsgCreateMerkleRootMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateMessageIdMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateNoopIsm
/hyperlane.core.interchain_security.v1.MsgCreateRoutingIsm
/hyperlane.core.interchain_security.v1.MsgRemoveRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgSetRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgUpdateRoutingIsmOwner
/hyperlane.core.post_dispatch.v1.MsgClaim
/hyperlane.core.post_dispatch.v1.MsgCreateIgp
/hyperlane.core.post_dispatch.v1.MsgCreateMerkleTreeHook
/hyperlane.core.post_dispatch.v1.MsgCreateNoopHook
/hyperlane.core.post_dispatch.v1.MsgPayForGas
/hyperlane.core.post_dispatch.v1.MsgSetDestinationGasConfig
/hyperlane.core.post_dispatch.v1.MsgSetIgpOwner
/hyperlane.core.v1.MsgCreateMailbox
/hyperlane.core.v1.MsgProcessMessage
/hyperlane.core.v1.MsgSetMailbox
/hyperlane.warp.v1.MsgCreateCollateralToken
/hyperlane.warp.v1.MsgCreateSyntheticToken
/hyperlane.warp.v1.MsgEnrollRemoteRouter
/hyperlane.warp.v1.MsgRemoteTransfer
/hyperlane.warp.v1.MsgSetToken
/hyperlane.warp.v1.MsgSetTokenResponse
/hyperlane.warp.v1.MsgUnrollRemoteRouter
/ibc.applications.interchain_accounts.controller.v1.MsgRegisterInterchainAccount
/ibc.applications.interchain_accounts.controller.v1.MsgSendTx
/ibc.applications.interchain_accounts.controller.v1.MsgUpdateParams
/ibc.applications.interchain_accounts.host.v1.MsgModuleQuerySafe
/ibc.applications.interchain_accounts.host.v1.MsgUpdateParams
/ibc.applications.transfer.v1.MsgTransfer
/ibc.applications.transfer.v1.MsgUpdateParams
/ibc.core.channel.v1.MsgAcknowledgement
/ibc.core.channel.v1.MsgChannelCloseConfirm
/ibc.core.channel.v1.MsgChannelCloseInit
/ibc.core.channel.v1.MsgChannelOpenAck
/ibc.core.channel.v1.MsgChannelOpenConfirm
/ibc.core.channel.v1.MsgChannelOpenInit
/ibc.core.channel.v1.MsgChannelOpenTry
/ibc.core.channel.v1.MsgChannelUpgradeAck
/ibc.core.channel.v1.MsgChannelUpgradeCancel
/ibc.core.channel.v1.MsgChannelUpgradeConfirm
/ibc.core.channel.v1.MsgChannelUpgradeInit
/ibc.core.channel.v1.MsgChannelUpgradeOpen
/ibc.core.channel.v1.MsgChannelUpgradeTimeout
/ibc.core.channel.v1.MsgChannelUpgradeTry
/ibc.core.channel.v1.MsgPruneAcknowledgements
/ibc.core.channel.v1.MsgRecvPacket
/ibc.core.channel.v1.MsgTimeout
/ibc.core.channel.v1.MsgTimeoutOnClose
/ibc.core.channel.v1.MsgUpdateParams
/ibc.core.client.v1.MsgCreateClient
/ibc.core.client.v1.MsgIBCSoftwareUpgrade
/ibc.core.client.v1.MsgRecoverClient
/ibc.core.client.v1.MsgSubmitMisbehaviour
/ibc.core.client.v1.MsgUpdateClient
/ibc.core.client.v1.MsgUpdateParams
/ibc.core.client.v1.MsgUpgradeClient
/ibc.core.connection.v1.MsgConnectionOpenAck
/ibc.core.connection.v1.MsgConnectionOpenConfirm
/ibc.core.connection.v1.MsgConnectionOpenInit
/ibc.core.connection.v1.MsgConnectionOpenTry
/ibc.core.connection.v1.MsgUpdateParams
Events
The following is an exhaustive list of supported events for app version 6.
celestia.blob.v1.EventPayForBlobs
celestia.blob.v1.EventUpdateBlobParams
celestia.minfee.v1.EventUpdateMinfeeParams
cosmos.authz.v1beta1.EventGrant
cosmos.authz.v1beta1.EventPruneExpiredGrants
cosmos.authz.v1beta1.EventRevoke
cosmos.base.abci.v1beta1.StringEvent
cosmos.distribution.v1beta1.ValidatorSlashEvent
cosmos.distribution.v1beta1.ValidatorSlashEventRecord
cosmos.distribution.v1beta1.ValidatorSlashEvents
cosmos.group.v1.EventCreateGroup
cosmos.group.v1.EventCreateGroupPolicy
cosmos.group.v1.EventExec
cosmos.group.v1.EventLeaveGroup
cosmos.group.v1.EventProposalPruned
cosmos.group.v1.EventSubmitProposal
cosmos.group.v1.EventTallyError
cosmos.group.v1.EventUpdateGroup
cosmos.group.v1.EventUpdateGroupPolicy
cosmos.group.v1.EventVote
cosmos.group.v1.EventWithdrawProposal
cosmos.tx.v1beta1.GetTxsEventRequest
cosmos.tx.v1beta1.GetTxsEventResponse
envoy.config.core.v3.EventServiceConfig
hyperlane.core.interchain_security.v1.EventAnnounceStorageLocation
hyperlane.core.interchain_security.v1.EventCreateMerkleRootMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateMessageIdMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateNoopIsm
hyperlane.core.interchain_security.v1.EventCreateRoutingIsm
hyperlane.core.interchain_security.v1.EventRemoveRoutingIsmDomain
hyperlane.core.interchain_security.v1.EventSetRoutingIsm
hyperlane.core.interchain_security.v1.EventSetRoutingIsmDomain
hyperlane.core.post_dispatch.v1.EventClaimIgp
hyperlane.core.post_dispatch.v1.EventCreateIgp
hyperlane.core.post_dispatch.v1.EventCreateMerkleTreeHook
hyperlane.core.post_dispatch.v1.EventCreateNoopHook
hyperlane.core.post_dispatch.v1.EventGasPayment
hyperlane.core.post_dispatch.v1.EventInsertedIntoTree
hyperlane.core.post_dispatch.v1.EventSetDestinationGasConfig
hyperlane.core.post_dispatch.v1.EventSetIgp
hyperlane.core.v1.EventCreateMailbox
hyperlane.core.v1.EventDispatch
hyperlane.core.v1.EventProcess
hyperlane.core.v1.EventSetMailbox
hyperlane.warp.v1.EventCreateCollateralToken
hyperlane.warp.v1.EventCreateSyntheticToken
hyperlane.warp.v1.EventEnrollRemoteRouter
hyperlane.warp.v1.EventReceiveRemoteTransfer
hyperlane.warp.v1.EventSendRemoteTransfer
hyperlane.warp.v1.EventSetToken
hyperlane.warp.v1.EventUnrollRemoteRouter
Types v7
Msgs
The following is an exhaustive list of supported Cosmos SDK Msgs for app version 7.
/celestia.blob.v1.MsgPayForBlobs
/celestia.blob.v1.MsgUpdateBlobParams
/celestia.forwarding.v1.MsgForward
/celestia.minfee.v1.MsgUpdateMinfeeParams
/celestia.signal.v1.MsgSignalVersion
/celestia.signal.v1.MsgTryUpgrade
/celestia.zkism.v1.MsgCreateInterchainSecurityModule
/celestia.zkism.v1.MsgSubmitMessages
/celestia.zkism.v1.MsgUpdateInterchainSecurityModule
/cosmos.auth.v1beta1.MsgUpdateParams
/cosmos.authz.v1beta1.MsgExec
/cosmos.authz.v1beta1.MsgGrant
/cosmos.authz.v1beta1.MsgPruneExpiredGrants
/cosmos.authz.v1beta1.MsgRevoke
/cosmos.bank.v1beta1.MsgMultiSend
/cosmos.bank.v1beta1.MsgSend
/cosmos.bank.v1beta1.MsgSetSendEnabled
/cosmos.bank.v1beta1.MsgUpdateParams
/cosmos.circuit.v1.MsgAuthorizeCircuitBreaker
/cosmos.circuit.v1.MsgResetCircuitBreaker
/cosmos.circuit.v1.MsgTripCircuitBreaker
/cosmos.consensus.v1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgCommunityPoolSpend
/cosmos.distribution.v1beta1.MsgDepositValidatorRewardsPool
/cosmos.distribution.v1beta1.MsgFundCommunityPool
/cosmos.distribution.v1beta1.MsgSetWithdrawAddress
/cosmos.distribution.v1beta1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgWithdrawDelegatorReward
/cosmos.distribution.v1beta1.MsgWithdrawValidatorCommission
/cosmos.evidence.v1beta1.MsgSubmitEvidence
/cosmos.feegrant.v1beta1.MsgGrantAllowance
/cosmos.feegrant.v1beta1.MsgPruneAllowances
/cosmos.feegrant.v1beta1.MsgRevokeAllowance
/cosmos.gov.v1.MsgCancelProposal
/cosmos.gov.v1.MsgDeposit
/cosmos.gov.v1.MsgExecLegacyContent
/cosmos.gov.v1.MsgSubmitProposal
/cosmos.gov.v1.MsgUpdateParams
/cosmos.gov.v1.MsgVote
/cosmos.gov.v1.MsgVoteWeighted
/cosmos.gov.v1beta1.MsgDeposit
/cosmos.gov.v1beta1.MsgSubmitProposal
/cosmos.gov.v1beta1.MsgVote
/cosmos.gov.v1beta1.MsgVoteWeighted
/cosmos.slashing.v1beta1.MsgUnjail
/cosmos.slashing.v1beta1.MsgUpdateParams
/cosmos.staking.v1beta1.MsgBeginRedelegate
/cosmos.staking.v1beta1.MsgCancelUnbondingDelegation
/cosmos.staking.v1beta1.MsgCreateValidator
/cosmos.staking.v1beta1.MsgDelegate
/cosmos.staking.v1beta1.MsgEditValidator
/cosmos.staking.v1beta1.MsgUndelegate
/cosmos.staking.v1beta1.MsgUpdateParams
/cosmos.upgrade.v1beta1.MsgCancelUpgrade
/cosmos.upgrade.v1beta1.MsgSoftwareUpgrade
/cosmos.vesting.v1beta1.MsgCreatePeriodicVestingAccount
/cosmos.vesting.v1beta1.MsgCreatePermanentLockedAccount
/cosmos.vesting.v1beta1.MsgCreateVestingAccount
/hyperlane.core.interchain_security.v1.MsgAnnounceValidator
/hyperlane.core.interchain_security.v1.MsgCreateMerkleRootMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateMessageIdMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateNoopIsm
/hyperlane.core.interchain_security.v1.MsgCreateRoutingIsm
/hyperlane.core.interchain_security.v1.MsgRemoveRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgSetRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgUpdateRoutingIsmOwner
/hyperlane.core.post_dispatch.v1.MsgClaim
/hyperlane.core.post_dispatch.v1.MsgCreateIgp
/hyperlane.core.post_dispatch.v1.MsgCreateMerkleTreeHook
/hyperlane.core.post_dispatch.v1.MsgCreateNoopHook
/hyperlane.core.post_dispatch.v1.MsgPayForGas
/hyperlane.core.post_dispatch.v1.MsgSetDestinationGasConfig
/hyperlane.core.post_dispatch.v1.MsgSetIgpOwner
/hyperlane.core.v1.MsgCreateMailbox
/hyperlane.core.v1.MsgProcessMessage
/hyperlane.core.v1.MsgSetMailbox
/hyperlane.warp.v1.MsgCreateCollateralToken
/hyperlane.warp.v1.MsgCreateSyntheticToken
/hyperlane.warp.v1.MsgEnrollRemoteRouter
/hyperlane.warp.v1.MsgRemoteTransfer
/hyperlane.warp.v1.MsgSetToken
/hyperlane.warp.v1.MsgSetTokenResponse
/hyperlane.warp.v1.MsgUnrollRemoteRouter
/ibc.applications.interchain_accounts.controller.v1.MsgRegisterInterchainAccount
/ibc.applications.interchain_accounts.controller.v1.MsgSendTx
/ibc.applications.interchain_accounts.controller.v1.MsgUpdateParams
/ibc.applications.interchain_accounts.host.v1.MsgModuleQuerySafe
/ibc.applications.interchain_accounts.host.v1.MsgUpdateParams
/ibc.applications.transfer.v1.MsgTransfer
/ibc.applications.transfer.v1.MsgUpdateParams
/ibc.core.channel.v1.MsgAcknowledgement
/ibc.core.channel.v1.MsgChannelCloseConfirm
/ibc.core.channel.v1.MsgChannelCloseInit
/ibc.core.channel.v1.MsgChannelOpenAck
/ibc.core.channel.v1.MsgChannelOpenConfirm
/ibc.core.channel.v1.MsgChannelOpenInit
/ibc.core.channel.v1.MsgChannelOpenTry
/ibc.core.channel.v1.MsgChannelUpgradeAck
/ibc.core.channel.v1.MsgChannelUpgradeCancel
/ibc.core.channel.v1.MsgChannelUpgradeConfirm
/ibc.core.channel.v1.MsgChannelUpgradeInit
/ibc.core.channel.v1.MsgChannelUpgradeOpen
/ibc.core.channel.v1.MsgChannelUpgradeTimeout
/ibc.core.channel.v1.MsgChannelUpgradeTry
/ibc.core.channel.v1.MsgPruneAcknowledgements
/ibc.core.channel.v1.MsgRecvPacket
/ibc.core.channel.v1.MsgTimeout
/ibc.core.channel.v1.MsgTimeoutOnClose
/ibc.core.channel.v1.MsgUpdateParams
/ibc.core.client.v1.MsgCreateClient
/ibc.core.client.v1.MsgIBCSoftwareUpgrade
/ibc.core.client.v1.MsgRecoverClient
/ibc.core.client.v1.MsgSubmitMisbehaviour
/ibc.core.client.v1.MsgUpdateClient
/ibc.core.client.v1.MsgUpdateParams
/ibc.core.client.v1.MsgUpgradeClient
/ibc.core.connection.v1.MsgConnectionOpenAck
/ibc.core.connection.v1.MsgConnectionOpenConfirm
/ibc.core.connection.v1.MsgConnectionOpenInit
/ibc.core.connection.v1.MsgConnectionOpenTry
/ibc.core.connection.v1.MsgUpdateParams
Events
The following is an exhaustive list of supported events for app version 7.
celestia.blob.v1.EventPayForBlobs
celestia.blob.v1.EventUpdateBlobParams
celestia.forwarding.v1.EventForwardingComplete
celestia.forwarding.v1.EventTokenForwarded
celestia.minfee.v1.EventUpdateMinfeeParams
celestia.zkism.v1.EventCreateInterchainSecurityModule
celestia.zkism.v1.EventSubmitMessages
celestia.zkism.v1.EventUpdateInterchainSecurityModule
cosmos.authz.v1beta1.EventGrant
cosmos.authz.v1beta1.EventPruneExpiredGrants
cosmos.authz.v1beta1.EventRevoke
cosmos.base.abci.v1beta1.StringEvent
cosmos.distribution.v1beta1.ValidatorSlashEvent
cosmos.distribution.v1beta1.ValidatorSlashEventRecord
cosmos.distribution.v1beta1.ValidatorSlashEvents
cosmos.group.v1.EventCreateGroup
cosmos.group.v1.EventCreateGroupPolicy
cosmos.group.v1.EventExec
cosmos.group.v1.EventLeaveGroup
cosmos.group.v1.EventProposalPruned
cosmos.group.v1.EventSubmitProposal
cosmos.group.v1.EventTallyError
cosmos.group.v1.EventUpdateGroup
cosmos.group.v1.EventUpdateGroupPolicy
cosmos.group.v1.EventVote
cosmos.group.v1.EventWithdrawProposal
cosmos.tx.v1beta1.GetTxsEventRequest
cosmos.tx.v1beta1.GetTxsEventResponse
envoy.config.core.v3.EventServiceConfig
hyperlane.core.interchain_security.v1.EventAnnounceStorageLocation
hyperlane.core.interchain_security.v1.EventCreateMerkleRootMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateMessageIdMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateNoopIsm
hyperlane.core.interchain_security.v1.EventCreateRoutingIsm
hyperlane.core.interchain_security.v1.EventRemoveRoutingIsmDomain
hyperlane.core.interchain_security.v1.EventSetRoutingIsm
hyperlane.core.interchain_security.v1.EventSetRoutingIsmDomain
hyperlane.core.post_dispatch.v1.EventClaimIgp
hyperlane.core.post_dispatch.v1.EventCreateIgp
hyperlane.core.post_dispatch.v1.EventCreateMerkleTreeHook
hyperlane.core.post_dispatch.v1.EventCreateNoopHook
hyperlane.core.post_dispatch.v1.EventGasPayment
hyperlane.core.post_dispatch.v1.EventInsertedIntoTree
hyperlane.core.post_dispatch.v1.EventSetDestinationGasConfig
hyperlane.core.post_dispatch.v1.EventSetIgp
hyperlane.core.v1.EventCreateMailbox
hyperlane.core.v1.EventDispatch
hyperlane.core.v1.EventProcess
hyperlane.core.v1.EventSetMailbox
hyperlane.warp.v1.EventCreateCollateralToken
hyperlane.warp.v1.EventCreateSyntheticToken
hyperlane.warp.v1.EventEnrollRemoteRouter
hyperlane.warp.v1.EventReceiveRemoteTransfer
hyperlane.warp.v1.EventSendRemoteTransfer
hyperlane.warp.v1.EventSetToken
hyperlane.warp.v1.EventUnrollRemoteRouter
Types v8
Msgs
The following is an exhaustive list of supported Cosmos SDK Msgs for app version 8.
/celestia.blob.v1.MsgPayForBlobs
/celestia.blob.v1.MsgUpdateBlobParams
/celestia.forwarding.v1.MsgForward
/celestia.minfee.v1.MsgUpdateMinfeeParams
/celestia.signal.v1.MsgSignalVersion
/celestia.signal.v1.MsgTryUpgrade
/celestia.zkism.v1.MsgCreateInterchainSecurityModule
/celestia.zkism.v1.MsgSubmitMessages
/celestia.zkism.v1.MsgUpdateInterchainSecurityModule
/cosmos.auth.v1beta1.MsgUpdateParams
/cosmos.authz.v1beta1.MsgExec
/cosmos.authz.v1beta1.MsgGrant
/cosmos.authz.v1beta1.MsgPruneExpiredGrants
/cosmos.authz.v1beta1.MsgRevoke
/cosmos.bank.v1beta1.MsgMultiSend
/cosmos.bank.v1beta1.MsgSend
/cosmos.bank.v1beta1.MsgSetSendEnabled
/cosmos.bank.v1beta1.MsgUpdateParams
/cosmos.circuit.v1.MsgAuthorizeCircuitBreaker
/cosmos.circuit.v1.MsgResetCircuitBreaker
/cosmos.circuit.v1.MsgTripCircuitBreaker
/cosmos.consensus.v1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgCommunityPoolSpend
/cosmos.distribution.v1beta1.MsgDepositValidatorRewardsPool
/cosmos.distribution.v1beta1.MsgFundCommunityPool
/cosmos.distribution.v1beta1.MsgSetWithdrawAddress
/cosmos.distribution.v1beta1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgWithdrawDelegatorReward
/cosmos.distribution.v1beta1.MsgWithdrawValidatorCommission
/cosmos.evidence.v1beta1.MsgSubmitEvidence
/cosmos.feegrant.v1beta1.MsgGrantAllowance
/cosmos.feegrant.v1beta1.MsgPruneAllowances
/cosmos.feegrant.v1beta1.MsgRevokeAllowance
/cosmos.gov.v1.MsgCancelProposal
/cosmos.gov.v1.MsgDeposit
/cosmos.gov.v1.MsgExecLegacyContent
/cosmos.gov.v1.MsgSubmitProposal
/cosmos.gov.v1.MsgUpdateParams
/cosmos.gov.v1.MsgVote
/cosmos.gov.v1.MsgVoteWeighted
/cosmos.gov.v1beta1.MsgDeposit
/cosmos.gov.v1beta1.MsgSubmitProposal
/cosmos.gov.v1beta1.MsgVote
/cosmos.gov.v1beta1.MsgVoteWeighted
/cosmos.slashing.v1beta1.MsgUnjail
/cosmos.slashing.v1beta1.MsgUpdateParams
/cosmos.staking.v1beta1.MsgBeginRedelegate
/cosmos.staking.v1beta1.MsgCancelUnbondingDelegation
/cosmos.staking.v1beta1.MsgCreateValidator
/cosmos.staking.v1beta1.MsgDelegate
/cosmos.staking.v1beta1.MsgEditValidator
/cosmos.staking.v1beta1.MsgUndelegate
/cosmos.staking.v1beta1.MsgUpdateParams
/cosmos.upgrade.v1beta1.MsgCancelUpgrade
/cosmos.upgrade.v1beta1.MsgSoftwareUpgrade
/cosmos.vesting.v1beta1.MsgCreatePeriodicVestingAccount
/cosmos.vesting.v1beta1.MsgCreatePermanentLockedAccount
/cosmos.vesting.v1beta1.MsgCreateVestingAccount
/hyperlane.core.interchain_security.v1.MsgAnnounceValidator
/hyperlane.core.interchain_security.v1.MsgCreateMerkleRootMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateMessageIdMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateNoopIsm
/hyperlane.core.interchain_security.v1.MsgCreateRoutingIsm
/hyperlane.core.interchain_security.v1.MsgRemoveRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgSetRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgUpdateRoutingIsmOwner
/hyperlane.core.post_dispatch.v1.MsgClaim
/hyperlane.core.post_dispatch.v1.MsgCreateIgp
/hyperlane.core.post_dispatch.v1.MsgCreateMerkleTreeHook
/hyperlane.core.post_dispatch.v1.MsgCreateNoopHook
/hyperlane.core.post_dispatch.v1.MsgPayForGas
/hyperlane.core.post_dispatch.v1.MsgSetDestinationGasConfig
/hyperlane.core.post_dispatch.v1.MsgSetIgpOwner
/hyperlane.core.v1.MsgCreateMailbox
/hyperlane.core.v1.MsgProcessMessage
/hyperlane.core.v1.MsgSetMailbox
/hyperlane.warp.v1.MsgCreateCollateralToken
/hyperlane.warp.v1.MsgCreateSyntheticToken
/hyperlane.warp.v1.MsgEnrollRemoteRouter
/hyperlane.warp.v1.MsgRemoteTransfer
/hyperlane.warp.v1.MsgSetToken
/hyperlane.warp.v1.MsgSetTokenResponse
/hyperlane.warp.v1.MsgUnrollRemoteRouter
/ibc.applications.interchain_accounts.controller.v1.MsgRegisterInterchainAccount
/ibc.applications.interchain_accounts.controller.v1.MsgSendTx
/ibc.applications.interchain_accounts.controller.v1.MsgUpdateParams
/ibc.applications.interchain_accounts.host.v1.MsgModuleQuerySafe
/ibc.applications.interchain_accounts.host.v1.MsgUpdateParams
/ibc.applications.transfer.v1.MsgTransfer
/ibc.applications.transfer.v1.MsgUpdateParams
/ibc.core.channel.v1.MsgAcknowledgement
/ibc.core.channel.v1.MsgChannelCloseConfirm
/ibc.core.channel.v1.MsgChannelCloseInit
/ibc.core.channel.v1.MsgChannelOpenAck
/ibc.core.channel.v1.MsgChannelOpenConfirm
/ibc.core.channel.v1.MsgChannelOpenInit
/ibc.core.channel.v1.MsgChannelOpenTry
/ibc.core.channel.v1.MsgChannelUpgradeAck
/ibc.core.channel.v1.MsgChannelUpgradeCancel
/ibc.core.channel.v1.MsgChannelUpgradeConfirm
/ibc.core.channel.v1.MsgChannelUpgradeInit
/ibc.core.channel.v1.MsgChannelUpgradeOpen
/ibc.core.channel.v1.MsgChannelUpgradeTimeout
/ibc.core.channel.v1.MsgChannelUpgradeTry
/ibc.core.channel.v1.MsgPruneAcknowledgements
/ibc.core.channel.v1.MsgRecvPacket
/ibc.core.channel.v1.MsgTimeout
/ibc.core.channel.v1.MsgTimeoutOnClose
/ibc.core.channel.v1.MsgUpdateParams
/ibc.core.client.v1.MsgCreateClient
/ibc.core.client.v1.MsgIBCSoftwareUpgrade
/ibc.core.client.v1.MsgRecoverClient
/ibc.core.client.v1.MsgSubmitMisbehaviour
/ibc.core.client.v1.MsgUpdateClient
/ibc.core.client.v1.MsgUpdateParams
/ibc.core.client.v1.MsgUpgradeClient
/ibc.core.connection.v1.MsgConnectionOpenAck
/ibc.core.connection.v1.MsgConnectionOpenConfirm
/ibc.core.connection.v1.MsgConnectionOpenInit
/ibc.core.connection.v1.MsgConnectionOpenTry
/ibc.core.connection.v1.MsgUpdateParams
Events
The following is an exhaustive list of supported events for app version 8.
celestia.blob.v1.EventPayForBlobs
celestia.blob.v1.EventUpdateBlobParams
celestia.forwarding.v1.EventTokenForwarded
celestia.minfee.v1.EventUpdateMinfeeParams
celestia.zkism.v1.EventCreateInterchainSecurityModule
celestia.zkism.v1.EventSubmitMessages
celestia.zkism.v1.EventUpdateInterchainSecurityModule
cosmos.authz.v1beta1.EventGrant
cosmos.authz.v1beta1.EventPruneExpiredGrants
cosmos.authz.v1beta1.EventRevoke
cosmos.base.abci.v1beta1.StringEvent
cosmos.distribution.v1beta1.ValidatorSlashEvent
cosmos.distribution.v1beta1.ValidatorSlashEventRecord
cosmos.distribution.v1beta1.ValidatorSlashEvents
cosmos.group.v1.EventCreateGroup
cosmos.group.v1.EventCreateGroupPolicy
cosmos.group.v1.EventExec
cosmos.group.v1.EventLeaveGroup
cosmos.group.v1.EventProposalPruned
cosmos.group.v1.EventSubmitProposal
cosmos.group.v1.EventTallyError
cosmos.group.v1.EventUpdateGroup
cosmos.group.v1.EventUpdateGroupPolicy
cosmos.group.v1.EventVote
cosmos.group.v1.EventWithdrawProposal
cosmos.tx.v1beta1.GetTxsEventRequest
cosmos.tx.v1beta1.GetTxsEventResponse
envoy.config.core.v3.EventServiceConfig
hyperlane.core.interchain_security.v1.EventAnnounceStorageLocation
hyperlane.core.interchain_security.v1.EventCreateMerkleRootMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateMessageIdMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateNoopIsm
hyperlane.core.interchain_security.v1.EventCreateRoutingIsm
hyperlane.core.interchain_security.v1.EventRemoveRoutingIsmDomain
hyperlane.core.interchain_security.v1.EventSetRoutingIsm
hyperlane.core.interchain_security.v1.EventSetRoutingIsmDomain
hyperlane.core.post_dispatch.v1.EventClaimIgp
hyperlane.core.post_dispatch.v1.EventCreateIgp
hyperlane.core.post_dispatch.v1.EventCreateMerkleTreeHook
hyperlane.core.post_dispatch.v1.EventCreateNoopHook
hyperlane.core.post_dispatch.v1.EventGasPayment
hyperlane.core.post_dispatch.v1.EventInsertedIntoTree
hyperlane.core.post_dispatch.v1.EventSetDestinationGasConfig
hyperlane.core.post_dispatch.v1.EventSetIgp
hyperlane.core.v1.EventCreateMailbox
hyperlane.core.v1.EventDispatch
hyperlane.core.v1.EventProcess
hyperlane.core.v1.EventSetMailbox
hyperlane.warp.v1.EventCreateCollateralToken
hyperlane.warp.v1.EventCreateSyntheticToken
hyperlane.warp.v1.EventEnrollRemoteRouter
hyperlane.warp.v1.EventReceiveRemoteTransfer
hyperlane.warp.v1.EventSendRemoteTransfer
hyperlane.warp.v1.EventSetToken
hyperlane.warp.v1.EventUnrollRemoteRouter
Types v9
Msgs
The following is an exhaustive list of supported Cosmos SDK Msgs for app version 9.
/celestia.blob.v1.MsgPayForBlobs
/celestia.blob.v1.MsgUpdateBlobParams
/celestia.forwarding.v1.MsgForward
/celestia.minfee.v1.MsgUpdateMinfeeParams
/celestia.signal.v1.MsgSignalVersion
/celestia.signal.v1.MsgTryUpgrade
/celestia.zkism.v1.MsgCreateInterchainSecurityModule
/celestia.zkism.v1.MsgSubmitMessages
/celestia.zkism.v1.MsgUpdateInterchainSecurityModule
/cosmos.auth.v1beta1.MsgUpdateParams
/cosmos.authz.v1beta1.MsgExec
/cosmos.authz.v1beta1.MsgGrant
/cosmos.authz.v1beta1.MsgPruneExpiredGrants
/cosmos.authz.v1beta1.MsgRevoke
/cosmos.bank.v1beta1.MsgMultiSend
/cosmos.bank.v1beta1.MsgSend
/cosmos.bank.v1beta1.MsgSetSendEnabled
/cosmos.bank.v1beta1.MsgUpdateParams
/cosmos.circuit.v1.MsgAuthorizeCircuitBreaker
/cosmos.circuit.v1.MsgResetCircuitBreaker
/cosmos.circuit.v1.MsgTripCircuitBreaker
/cosmos.consensus.v1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgCommunityPoolSpend
/cosmos.distribution.v1beta1.MsgDepositValidatorRewardsPool
/cosmos.distribution.v1beta1.MsgFundCommunityPool
/cosmos.distribution.v1beta1.MsgSetWithdrawAddress
/cosmos.distribution.v1beta1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgWithdrawDelegatorReward
/cosmos.distribution.v1beta1.MsgWithdrawValidatorCommission
/cosmos.evidence.v1beta1.MsgSubmitEvidence
/cosmos.feegrant.v1beta1.MsgGrantAllowance
/cosmos.feegrant.v1beta1.MsgPruneAllowances
/cosmos.feegrant.v1beta1.MsgRevokeAllowance
/cosmos.gov.v1.MsgCancelProposal
/cosmos.gov.v1.MsgDeposit
/cosmos.gov.v1.MsgExecLegacyContent
/cosmos.gov.v1.MsgSubmitProposal
/cosmos.gov.v1.MsgUpdateParams
/cosmos.gov.v1.MsgVote
/cosmos.gov.v1.MsgVoteWeighted
/cosmos.gov.v1beta1.MsgDeposit
/cosmos.gov.v1beta1.MsgSubmitProposal
/cosmos.gov.v1beta1.MsgVote
/cosmos.gov.v1beta1.MsgVoteWeighted
/cosmos.slashing.v1beta1.MsgUnjail
/cosmos.slashing.v1beta1.MsgUpdateParams
/cosmos.staking.v1beta1.MsgBeginRedelegate
/cosmos.staking.v1beta1.MsgCancelUnbondingDelegation
/cosmos.staking.v1beta1.MsgCreateValidator
/cosmos.staking.v1beta1.MsgDelegate
/cosmos.staking.v1beta1.MsgEditValidator
/cosmos.staking.v1beta1.MsgUndelegate
/cosmos.staking.v1beta1.MsgUpdateParams
/cosmos.upgrade.v1beta1.MsgCancelUpgrade
/cosmos.upgrade.v1beta1.MsgSoftwareUpgrade
/cosmos.vesting.v1beta1.MsgCreatePeriodicVestingAccount
/cosmos.vesting.v1beta1.MsgCreatePermanentLockedAccount
/cosmos.vesting.v1beta1.MsgCreateVestingAccount
/hyperlane.core.interchain_security.v1.MsgAnnounceValidator
/hyperlane.core.interchain_security.v1.MsgCreateMerkleRootMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateMessageIdMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateNoopIsm
/hyperlane.core.interchain_security.v1.MsgCreateRoutingIsm
/hyperlane.core.interchain_security.v1.MsgRemoveRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgSetRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgUpdateRoutingIsmOwner
/hyperlane.core.post_dispatch.v1.MsgClaim
/hyperlane.core.post_dispatch.v1.MsgCreateIgp
/hyperlane.core.post_dispatch.v1.MsgCreateMerkleTreeHook
/hyperlane.core.post_dispatch.v1.MsgCreateNoopHook
/hyperlane.core.post_dispatch.v1.MsgPayForGas
/hyperlane.core.post_dispatch.v1.MsgSetDestinationGasConfig
/hyperlane.core.post_dispatch.v1.MsgSetIgpOwner
/hyperlane.core.v1.MsgCreateMailbox
/hyperlane.core.v1.MsgProcessMessage
/hyperlane.core.v1.MsgSetMailbox
/hyperlane.warp.v1.MsgCreateCollateralToken
/hyperlane.warp.v1.MsgCreateSyntheticToken
/hyperlane.warp.v1.MsgEnrollRemoteRouter
/hyperlane.warp.v1.MsgRemoteTransfer
/hyperlane.warp.v1.MsgSetToken
/hyperlane.warp.v1.MsgSetTokenResponse
/hyperlane.warp.v1.MsgUnrollRemoteRouter
/ibc.applications.interchain_accounts.controller.v1.MsgRegisterInterchainAccount
/ibc.applications.interchain_accounts.controller.v1.MsgSendTx
/ibc.applications.interchain_accounts.controller.v1.MsgUpdateParams
/ibc.applications.interchain_accounts.host.v1.MsgModuleQuerySafe
/ibc.applications.interchain_accounts.host.v1.MsgUpdateParams
/ibc.applications.transfer.v1.MsgTransfer
/ibc.applications.transfer.v1.MsgUpdateParams
/ibc.core.channel.v1.MsgAcknowledgement
/ibc.core.channel.v1.MsgChannelCloseConfirm
/ibc.core.channel.v1.MsgChannelCloseInit
/ibc.core.channel.v1.MsgChannelOpenAck
/ibc.core.channel.v1.MsgChannelOpenConfirm
/ibc.core.channel.v1.MsgChannelOpenInit
/ibc.core.channel.v1.MsgChannelOpenTry
/ibc.core.channel.v1.MsgChannelUpgradeAck
/ibc.core.channel.v1.MsgChannelUpgradeCancel
/ibc.core.channel.v1.MsgChannelUpgradeConfirm
/ibc.core.channel.v1.MsgChannelUpgradeInit
/ibc.core.channel.v1.MsgChannelUpgradeOpen
/ibc.core.channel.v1.MsgChannelUpgradeTimeout
/ibc.core.channel.v1.MsgChannelUpgradeTry
/ibc.core.channel.v1.MsgPruneAcknowledgements
/ibc.core.channel.v1.MsgRecvPacket
/ibc.core.channel.v1.MsgTimeout
/ibc.core.channel.v1.MsgTimeoutOnClose
/ibc.core.channel.v1.MsgUpdateParams
/ibc.core.client.v1.MsgCreateClient
/ibc.core.client.v1.MsgIBCSoftwareUpgrade
/ibc.core.client.v1.MsgRecoverClient
/ibc.core.client.v1.MsgSubmitMisbehaviour
/ibc.core.client.v1.MsgUpdateClient
/ibc.core.client.v1.MsgUpdateParams
/ibc.core.client.v1.MsgUpgradeClient
/ibc.core.connection.v1.MsgConnectionOpenAck
/ibc.core.connection.v1.MsgConnectionOpenConfirm
/ibc.core.connection.v1.MsgConnectionOpenInit
/ibc.core.connection.v1.MsgConnectionOpenTry
/ibc.core.connection.v1.MsgUpdateParams
Events
The following is an exhaustive list of supported events for app version 9.
celestia.blob.v1.EventPayForBlobs
celestia.blob.v1.EventUpdateBlobParams
celestia.forwarding.v1.EventTokenForwarded
celestia.minfee.v1.EventUpdateMinfeeParams
celestia.zkism.v1.EventCreateInterchainSecurityModule
celestia.zkism.v1.EventSubmitMessages
celestia.zkism.v1.EventUpdateInterchainSecurityModule
cosmos.authz.v1beta1.EventGrant
cosmos.authz.v1beta1.EventPruneExpiredGrants
cosmos.authz.v1beta1.EventRevoke
cosmos.base.abci.v1beta1.StringEvent
cosmos.distribution.v1beta1.ValidatorSlashEvent
cosmos.distribution.v1beta1.ValidatorSlashEventRecord
cosmos.distribution.v1beta1.ValidatorSlashEvents
cosmos.group.v1.EventCreateGroup
cosmos.group.v1.EventCreateGroupPolicy
cosmos.group.v1.EventExec
cosmos.group.v1.EventLeaveGroup
cosmos.group.v1.EventProposalPruned
cosmos.group.v1.EventSubmitProposal
cosmos.group.v1.EventTallyError
cosmos.group.v1.EventUpdateGroup
cosmos.group.v1.EventUpdateGroupPolicy
cosmos.group.v1.EventVote
cosmos.group.v1.EventWithdrawProposal
cosmos.tx.v1beta1.GetTxsEventRequest
cosmos.tx.v1beta1.GetTxsEventResponse
envoy.config.core.v3.EventServiceConfig
hyperlane.core.interchain_security.v1.EventAnnounceStorageLocation
hyperlane.core.interchain_security.v1.EventCreateMerkleRootMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateMessageIdMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateNoopIsm
hyperlane.core.interchain_security.v1.EventCreateRoutingIsm
hyperlane.core.interchain_security.v1.EventRemoveRoutingIsmDomain
hyperlane.core.interchain_security.v1.EventSetRoutingIsm
hyperlane.core.interchain_security.v1.EventSetRoutingIsmDomain
hyperlane.core.post_dispatch.v1.EventClaimIgp
hyperlane.core.post_dispatch.v1.EventCreateIgp
hyperlane.core.post_dispatch.v1.EventCreateMerkleTreeHook
hyperlane.core.post_dispatch.v1.EventCreateNoopHook
hyperlane.core.post_dispatch.v1.EventGasPayment
hyperlane.core.post_dispatch.v1.EventInsertedIntoTree
hyperlane.core.post_dispatch.v1.EventSetDestinationGasConfig
hyperlane.core.post_dispatch.v1.EventSetIgp
hyperlane.core.v1.EventCreateMailbox
hyperlane.core.v1.EventDispatch
hyperlane.core.v1.EventProcess
hyperlane.core.v1.EventSetMailbox
hyperlane.warp.v1.EventCreateCollateralToken
hyperlane.warp.v1.EventCreateSyntheticToken
hyperlane.warp.v1.EventEnrollRemoteRouter
hyperlane.warp.v1.EventReceiveRemoteTransfer
hyperlane.warp.v1.EventSendRemoteTransfer
hyperlane.warp.v1.EventSetToken
hyperlane.warp.v1.EventUnrollRemoteRouter
Types v10
Msgs
The following is an exhaustive list of supported Cosmos SDK Msgs for app version 10.
/celestia.blob.v1.MsgPayForBlobs
/celestia.blob.v1.MsgUpdateBlobParams
/celestia.forwarding.v1.MsgForward
/celestia.minfee.v1.MsgUpdateMinfeeParams
/celestia.signal.v1.MsgSignalVersion
/celestia.signal.v1.MsgTryUpgrade
/celestia.zkism.v1.MsgCreateInterchainSecurityModule
/celestia.zkism.v1.MsgSubmitMessages
/celestia.zkism.v1.MsgUpdateInterchainSecurityModule
/cosmos.auth.v1beta1.MsgUpdateParams
/cosmos.authz.v1beta1.MsgExec
/cosmos.authz.v1beta1.MsgGrant
/cosmos.authz.v1beta1.MsgPruneExpiredGrants
/cosmos.authz.v1beta1.MsgRevoke
/cosmos.bank.v1beta1.MsgMultiSend
/cosmos.bank.v1beta1.MsgSend
/cosmos.bank.v1beta1.MsgSetSendEnabled
/cosmos.bank.v1beta1.MsgUpdateParams
/cosmos.circuit.v1.MsgAuthorizeCircuitBreaker
/cosmos.circuit.v1.MsgResetCircuitBreaker
/cosmos.circuit.v1.MsgTripCircuitBreaker
/cosmos.consensus.v1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgCommunityPoolSpend
/cosmos.distribution.v1beta1.MsgDepositValidatorRewardsPool
/cosmos.distribution.v1beta1.MsgFundCommunityPool
/cosmos.distribution.v1beta1.MsgSetWithdrawAddress
/cosmos.distribution.v1beta1.MsgUpdateParams
/cosmos.distribution.v1beta1.MsgWithdrawDelegatorReward
/cosmos.distribution.v1beta1.MsgWithdrawValidatorCommission
/cosmos.evidence.v1beta1.MsgSubmitEvidence
/cosmos.feegrant.v1beta1.MsgGrantAllowance
/cosmos.feegrant.v1beta1.MsgPruneAllowances
/cosmos.feegrant.v1beta1.MsgRevokeAllowance
/cosmos.gov.v1.MsgCancelProposal
/cosmos.gov.v1.MsgDeposit
/cosmos.gov.v1.MsgExecLegacyContent
/cosmos.gov.v1.MsgSubmitProposal
/cosmos.gov.v1.MsgUpdateParams
/cosmos.gov.v1.MsgVote
/cosmos.gov.v1.MsgVoteWeighted
/cosmos.gov.v1beta1.MsgDeposit
/cosmos.gov.v1beta1.MsgSubmitProposal
/cosmos.gov.v1beta1.MsgVote
/cosmos.gov.v1beta1.MsgVoteWeighted
/cosmos.slashing.v1beta1.MsgUnjail
/cosmos.slashing.v1beta1.MsgUpdateParams
/cosmos.staking.v1beta1.MsgBeginRedelegate
/cosmos.staking.v1beta1.MsgCancelUnbondingDelegation
/cosmos.staking.v1beta1.MsgCreateValidator
/cosmos.staking.v1beta1.MsgDelegate
/cosmos.staking.v1beta1.MsgEditValidator
/cosmos.staking.v1beta1.MsgUndelegate
/cosmos.staking.v1beta1.MsgUpdateParams
/cosmos.upgrade.v1beta1.MsgCancelUpgrade
/cosmos.upgrade.v1beta1.MsgSoftwareUpgrade
/cosmos.vesting.v1beta1.MsgCreatePeriodicVestingAccount
/cosmos.vesting.v1beta1.MsgCreatePermanentLockedAccount
/cosmos.vesting.v1beta1.MsgCreateVestingAccount
/hyperlane.core.interchain_security.v1.MsgAnnounceValidator
/hyperlane.core.interchain_security.v1.MsgCreateMerkleRootMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateMessageIdMultisigIsm
/hyperlane.core.interchain_security.v1.MsgCreateNoopIsm
/hyperlane.core.interchain_security.v1.MsgCreateRoutingIsm
/hyperlane.core.interchain_security.v1.MsgRemoveRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgSetRoutingIsmDomain
/hyperlane.core.interchain_security.v1.MsgUpdateRoutingIsmOwner
/hyperlane.core.post_dispatch.v1.MsgClaim
/hyperlane.core.post_dispatch.v1.MsgCreateIgp
/hyperlane.core.post_dispatch.v1.MsgCreateMerkleTreeHook
/hyperlane.core.post_dispatch.v1.MsgCreateNoopHook
/hyperlane.core.post_dispatch.v1.MsgPayForGas
/hyperlane.core.post_dispatch.v1.MsgSetDestinationGasConfig
/hyperlane.core.post_dispatch.v1.MsgSetIgpOwner
/hyperlane.core.v1.MsgCreateMailbox
/hyperlane.core.v1.MsgProcessMessage
/hyperlane.core.v1.MsgSetMailbox
/hyperlane.warp.v1.MsgCreateCollateralToken
/hyperlane.warp.v1.MsgCreateSyntheticToken
/hyperlane.warp.v1.MsgEnrollRemoteRouter
/hyperlane.warp.v1.MsgRemoteTransfer
/hyperlane.warp.v1.MsgSetToken
/hyperlane.warp.v1.MsgSetTokenResponse
/hyperlane.warp.v1.MsgUnrollRemoteRouter
/ibc.applications.interchain_accounts.controller.v1.MsgRegisterInterchainAccount
/ibc.applications.interchain_accounts.controller.v1.MsgSendTx
/ibc.applications.interchain_accounts.controller.v1.MsgUpdateParams
/ibc.applications.interchain_accounts.host.v1.MsgModuleQuerySafe
/ibc.applications.interchain_accounts.host.v1.MsgUpdateParams
/ibc.applications.transfer.v1.MsgTransfer
/ibc.applications.transfer.v1.MsgUpdateParams
/ibc.core.channel.v1.MsgAcknowledgement
/ibc.core.channel.v1.MsgChannelCloseConfirm
/ibc.core.channel.v1.MsgChannelCloseInit
/ibc.core.channel.v1.MsgChannelOpenAck
/ibc.core.channel.v1.MsgChannelOpenConfirm
/ibc.core.channel.v1.MsgChannelOpenInit
/ibc.core.channel.v1.MsgChannelOpenTry
/ibc.core.channel.v1.MsgChannelUpgradeAck
/ibc.core.channel.v1.MsgChannelUpgradeCancel
/ibc.core.channel.v1.MsgChannelUpgradeConfirm
/ibc.core.channel.v1.MsgChannelUpgradeInit
/ibc.core.channel.v1.MsgChannelUpgradeOpen
/ibc.core.channel.v1.MsgChannelUpgradeTimeout
/ibc.core.channel.v1.MsgChannelUpgradeTry
/ibc.core.channel.v1.MsgPruneAcknowledgements
/ibc.core.channel.v1.MsgRecvPacket
/ibc.core.channel.v1.MsgTimeout
/ibc.core.channel.v1.MsgTimeoutOnClose
/ibc.core.channel.v1.MsgUpdateParams
/ibc.core.client.v1.MsgCreateClient
/ibc.core.client.v1.MsgIBCSoftwareUpgrade
/ibc.core.client.v1.MsgRecoverClient
/ibc.core.client.v1.MsgSubmitMisbehaviour
/ibc.core.client.v1.MsgUpdateClient
/ibc.core.client.v1.MsgUpdateParams
/ibc.core.client.v1.MsgUpgradeClient
/ibc.core.connection.v1.MsgConnectionOpenAck
/ibc.core.connection.v1.MsgConnectionOpenConfirm
/ibc.core.connection.v1.MsgConnectionOpenInit
/ibc.core.connection.v1.MsgConnectionOpenTry
/ibc.core.connection.v1.MsgUpdateParams
Events
The following is an exhaustive list of supported events for app version 10.
celestia.blob.v1.EventPayForBlobs
celestia.blob.v1.EventUpdateBlobParams
celestia.forwarding.v1.EventTokenForwarded
celestia.minfee.v1.EventUpdateMinfeeParams
celestia.zkism.v1.EventCreateInterchainSecurityModule
celestia.zkism.v1.EventSubmitMessages
celestia.zkism.v1.EventUpdateInterchainSecurityModule
cosmos.authz.v1beta1.EventGrant
cosmos.authz.v1beta1.EventPruneExpiredGrants
cosmos.authz.v1beta1.EventRevoke
cosmos.base.abci.v1beta1.StringEvent
cosmos.distribution.v1beta1.ValidatorSlashEvent
cosmos.distribution.v1beta1.ValidatorSlashEventRecord
cosmos.distribution.v1beta1.ValidatorSlashEvents
cosmos.group.v1.EventCreateGroup
cosmos.group.v1.EventCreateGroupPolicy
cosmos.group.v1.EventExec
cosmos.group.v1.EventLeaveGroup
cosmos.group.v1.EventProposalPruned
cosmos.group.v1.EventSubmitProposal
cosmos.group.v1.EventTallyError
cosmos.group.v1.EventUpdateGroup
cosmos.group.v1.EventUpdateGroupPolicy
cosmos.group.v1.EventVote
cosmos.group.v1.EventWithdrawProposal
cosmos.tx.v1beta1.GetTxsEventRequest
cosmos.tx.v1beta1.GetTxsEventResponse
envoy.config.core.v3.EventServiceConfig
hyperlane.core.interchain_security.v1.EventAnnounceStorageLocation
hyperlane.core.interchain_security.v1.EventCreateMerkleRootMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateMessageIdMultisigIsm
hyperlane.core.interchain_security.v1.EventCreateNoopIsm
hyperlane.core.interchain_security.v1.EventCreateRoutingIsm
hyperlane.core.interchain_security.v1.EventRemoveRoutingIsmDomain
hyperlane.core.interchain_security.v1.EventSetRoutingIsm
hyperlane.core.interchain_security.v1.EventSetRoutingIsmDomain
hyperlane.core.post_dispatch.v1.EventClaimIgp
hyperlane.core.post_dispatch.v1.EventCreateIgp
hyperlane.core.post_dispatch.v1.EventCreateMerkleTreeHook
hyperlane.core.post_dispatch.v1.EventCreateNoopHook
hyperlane.core.post_dispatch.v1.EventGasPayment
hyperlane.core.post_dispatch.v1.EventInsertedIntoTree
hyperlane.core.post_dispatch.v1.EventSetDestinationGasConfig
hyperlane.core.post_dispatch.v1.EventSetIgp
hyperlane.core.v1.EventCreateMailbox
hyperlane.core.v1.EventDispatch
hyperlane.core.v1.EventProcess
hyperlane.core.v1.EventSetMailbox
hyperlane.warp.v1.EventCreateCollateralToken
hyperlane.warp.v1.EventCreateSyntheticToken
hyperlane.warp.v1.EventEnrollRemoteRouter
hyperlane.warp.v1.EventReceiveRemoteTransfer
hyperlane.warp.v1.EventSendRemoteTransfer
hyperlane.warp.v1.EventSetToken
hyperlane.warp.v1.EventUnrollRemoteRouter
Transaction Client
Abstract
The Transaction Client (TxClient) provides a high-level abstraction for constructing, signing, broadcasting, and confirming transactions on Celestia chain. It handles sequence mismatches, mempool evictions, rejections and provides parallel transaction submission via worker accounts. The client is built around two reliable submission strategies: ordered (sequential) and unordered (parallel) submissions.
Protocol/Component Description
Gas Estimator
The gas estimation service is an external dependency that provides accurate gas and fee calculations for transaction submission.
Key Functionality:
TxClient calls the gas estimation service during broadcast to ensure transactions have appropriate gas limits and fees, handling sequence mismatches automatically through re-signing with corrected sequences.
Note: Gas estimation is only necessary when the user did not set gas limit and gas price in tx options.
Gas Estimator APIs:
EstimateGasPriceAndUsage(ctx context.Context, msgs []sdktypes.Msg, priority gasestimation.TxPriority, opts ...TxOption) (gasPrice float64, gasUsed uint64, err error)EstimateGasPrice(ctx context.Context, priority gasestimation.TxPriority) (float64, error)
Tx Flow
Below will be described tx flow from submission to broadcasting it on celestia chain to confirmation and how transaction client handles it. It will be split into 3 sub-sections.
Submission
Important: Currently, only the below submission patterns are reliable for submitting transactions. Other patterns like sending multiple transactions from one account without waiting for confirmation will likely cause sequence mismatches and failures.
Ordered Submission
Characteristics: Low Throughput, Sequential Submission, Less error prone
- Single Account: All transactions signed by one account
- Sequential: Max one tx per block, each tx must be confirmed before subsequent can be resubmitted
- Ordering: Transactions will likely be processed in submission order
- Low Throughput: One tx per block per account
- Use Case:
- Applications and users requiring all blobs to be signed by a single account and reliably executed.
APIs:
-
SubmitTx: Sequential submission for SDK txs (no worker queue).
-
Process: Build transaction → Broadcast → Confirm
func (client *TxClient) SubmitTx(ctx context.Context, msgs []sdktypes.Msg, opts ...TxOption) (*TxResponse, error)
-
-
SubmitPayForBlob: Sequential submission with default account (no worker queue).
-
Process: Create PFB with default account → Broadcast → Confirm
func (client *TxClient) SubmitPayForBlob(ctx context.Context, blobs []*share.Blob, opts ...TxOption) (*TxResponse, error)
-
-
SubmitPayForBlobWithAccount: Sequential submission with a specified account (bypasses worker queue).
-
Process: Create PFB with specified account → Broadcast → Confirmation
func (client *TxClient) SubmitPayForBlobWithAccount(ctx context.Context, accountName string, blobs []*share.Blob, opts ...TxOption) (*TxResponse, error)
-
Unordered Submission
Characteristics: High Throughput, Parallel submission, No Ordering
- Worker Accounts: A pool of accounts is created by the primary account, each fee-granted with unlimited allowances.
- Worker Queue: Transactions are queued and dispatched to available workers.
- Parallel Workers:
- Worker 0 = primary account
- Workers >0 = additional fee-granted accounts
- High Throughput: Multiple transactions can be submitted and processed per block concurrently, without sequence contention.
- No Ordering Guarantees: Execution order is nondeterministic; workers process transactions as they become available.
- Fee Grants: All fees are covered by the primary account, so workers operate without individual balance management.
- Account Reuse: Worker accounts are persisted across runtimes when parallel submission is enabled.
- Use Case: Best suited for applications that prioritize throughput over ordering.
Note: If initialized with only one worker, this mode behaves identically to Sequential Submission (one tx per block).
APIs:
-
SubmitPayForBlobToQueue: Uses worker queue for parallel or sequential (1 worker) submissions.
-
Process: Job queued → Worker assignment → PayForBlob creation → Broadcast → Confirmation
func (client *TxClient) SubmitPayForBlobToQueue(ctx context.Context, blobs []*share.Blob, opts ...TxOption) (*TxResponse, error)
-
-
QueueBlob: Direct job submission to worker queue.
-
Process: Job queued directly → Worker assignment → PayForBlob creation → Broadcast → Confirmation
func (client *TxClient) QueueBlob(ctx context.Context, resultC chan SubmissionResult, blobs []*share.Blob, opts ...TxOption)
-
All submission APIs ultimately delegate into the same broadcast and confirmation methods, they differ only in account selection, tx types and whether jobs go through the worker queue.
Broadcast
Broadcasting steps are universal across SDK transactions and blob transactions.
Process:
-
Build & Sign: Transaction is built and signed using the Signer
-
Gas Estimation:
- If no gas provided, simulate with minimal fee
- Call gas estimation service to determine gas usage and price
- If simulation fails due to a sequence mismatch:
- Update local sequence to expected.
- Resign and retry gas estimation.
-
Fee Setting: Fee is computed as
ceil(minGasPrice * gasLimit)unless explicitly set by the user -
Broadcast: Transaction is encoded and submitted via gRPC:
- Single-endpoint mode: Send to the default RPC endpoint.
- Multi-endpoint mode: Broadcast to all endpoints, accept the first success and cancel the rest; if all fail, return the first error.
-
Broadcast Error Handling: Common to both single and multi-endpoint modes.
- Sequence mismatch during CheckTx (mempool validation):
- Retry with corrected sequence until success or another failure.
- Update the signer’s local sequence to the expected value returned by the node.
- Reasoning: Without updating to the chain’s expected sequence, the client’s local signer falls behind and stalls. Once stalled, no new transactions can be submitted until the process is manually reset.
- Other rejections:
- Tendermint/CometBFT does not throw mempool errors for application rejections; they are set in the transaction response.
- The client must parse the response code:
-
0(
abci.CodeTypeOK) - accepted into mempool. -
Non-zero - tx was rejected; populate and return
BroadcastTxError.type BroadcastTxError struct { TxHash string // Transaction hash Code uint32 // Error code from node ErrorLog string // Detailed error message }
-
- Sequence mismatch during CheckTx (mempool validation):
-
Transaction Entry: On success, record (
signer,sequence,txBytes). -
Sequence Increment: After successful broadcast, increment the signer’s local sequence by calling signer.SetSequence()
Confirmation
After broadcast, the TxClient continuously polls the chain for transaction status until resolution. This is the tx confirmation life cycle:
-
Pending: Transaction in the mempool but not yet included, continue polling
-
Committed: Transaction included in a block.
-
If execution succeeded (response code =
abci.CodeTypeOK): return success -
If execution failed (any other response code):
- Populate
ExecutionErrorand return it to the user
type ExecutionError struct { TxHash string // Transaction hash Code uint32 // Execution result code ErrorLog string // Execution error details } - Populate
-
-
Rejected: Transaction was explicitly refused by the node during
ReCheck()(after each block commit).- Retrieve tx sequence from the tracker.
- Roll back the sequence to the retrieved tx sequence.
- Construct and return a rejection error with the tx hash and response code. (no specific error type)
-
Evicted: Transaction dropped from mempool (low fees, mempool full).
- The client resubmits using txBytes stored in the tracker.
- If resubmission fails (e.g. sequence mismatch):
- Do not resign with a new sequence. Eviction isn't final, another node might still propose this tx and resigning risks duplicate inclusion.
- Start a 1-minute eviction timeout window. If the tx is not confirmed within timeout period, construct and return an eviction error. (no specific error type)
- If resubmission is successful:
- The same tx is re-added to the node's mempool
- Continue polling until the updated status is resolved
-
Unknown/Not Found: Tx is neither evicted nor rejected or confirmed. Return error to the user that tx is unknown.
-
Once transactions are concluded (rejected/evicted/confirmed) they should get pruned from the tracker before function returns.
Message Structure/Communication Format
The client communicates with Celestia full nodes through gRPC services for transaction broadcasting, status checking, and gas estimation.
Transaction Broadcast
Request: BroadcastTxRequest { TxBytes, Mode }
Response: BroadcastTxResponse { TxHash, Code, RawLog }
Transaction Status
Request: TxStatusRequest { TxId }
Response: TxStatusResponse { Status, Height, ExecutionCode, Error }
Gas Estimation
Request: EstimateGasPriceAndUsageRequest { TxBytes, TxPriority }
Response: EstimatedGasUsed, EstimatedGasPrice
Assumptions and Considerations
-
Trusted Node: The client depends on a trusted consensus node for account state, sequence numbers, and gas estimation (no proof verification).
-
Eviction Behavior: Evictions are local to a node. A transaction evicted by one node may still be proposed by another, so users must not re-sign the transaction immediately to avoid double-spending.
-
Submission Modes: Only sequential (single account) or parallel (worker accounts with fee grants) are safe; other patterns may lead to sequence mismatches.
Implementation
TxClient implementation can be found in the celestia-app repo in the pkg/user directory
Tx Client v2 – Sequential Submission Queue
Overview
Tx Client v2 enforces per-account sequential transaction submission to prevent sequence races and minimize transaction failures.
Key properties
- Transactions are signed and broadcast strictly in sequence order
- A transaction is never re-signed, only resubmitted (which means resubmitted using the original signed bytes).
Assumptions
- The transactions conform to minimum fee requirements, so a transaction will eventually be included in a block after a bounded number of retries, given that the signer has enough funds in its account.
Error Handling
Errors are classified based on whether progress can be made without user intervention.
- Retryable: the client can resubmit the transaction.
- Terminal: the error is returned to the user and further progress requires user action.
Non-sequence errors
Errors that are not related to account sequence numbers.
Retryable
- Network errors
- Application errors like
ErrMempoolIsFull
Retryable Behavior
- Retry submission until accepted or a terminal error occurs.
Terminal
- Application errors like
ErrTxTooLarge
Terminal Behavior
- Return the error to the user immediately.
Sequence mismatch errors
Sequence mismatch errors occur when the node's expected account sequence differs from the client's sequence during submission.
Case 1: Expected sequence < client sequence
Indicates eviction or rejection of one or more previously submitted transactions that is not yet known to the client (e.g. eviction or rejection during ReCheckTx).
Case 1 Behavior
- Pause broadcasting.
- Query the status of transactions in the range
[expected_sequence, last_submitted_sequence].
For each transaction in order:
- Evicted (Retryable)
- Resubmit the transaction using the original signed bytes.
- Rejected (Terminal)
- Roll back the client sequence to the rejected transaction's sequence.
- Return the rejection error to the user.
Case 2: Expected sequence > client sequence
Indicates that the node's CheckTx state has advanced beyond the client's state.
This can happen for one of the following reasons:
- The transaction was evicted on the current node (thus not in the mempool), but was included in a block on another node.
- A different transaction with the same sequence was included in a block, implying that a transaction for the signer was submitted outside of the tx client.
Case 2 Behavior
- Pause broadcasting.
- Query the status of the transaction with the conflicting sequence.
- If the transaction is Committed:
- Treat the mismatch as Retryable.
- Advance client state accordingly.
- Resume broadcasting.
- If the transaction is not committed:
- Treat the mismatch as Terminal.
- Return an error indicating that the client state has conflicting transaction with same sequence number.
Confirmation and Monitoring
Transaction statuses are obtained via batched status queries using the tx_status_batch RPC method over a bounded set of pending transactions.
Transaction States
Pending
- No action required.
Committed
- The transaction was included in a block.
- Remove from the queue.
- Return success with execution metadata.
Committed with execution error
- The transaction was included in a block but failed during execution.
- Remove from the queue.
- Return execution error with metadata.
Evicted
- Broadcasting is paused.
- Resubmit the transaction.
- Resume broadcasting.
Rejected
- Broadcasting is paused.
- Roll back the sequence to the first rejected transaction.
- Return rejection error to the user.
Unknown
- The transaction is neither evicted, rejected, nor committed.
- Return an error indicating that the transaction status is unknown.
Implementation Notes
- Each account has a submission queue that owns transaction sequencing, signing, and submission.
- Confirmations are processed by a separate confirmation queue/worker that polls transaction statuses.
- Confirmation results are fed back to the submission queue, which remains the single point of coordination per account.
Fibre DA Specification
This is a specification of a DA protocol that extends Celestia. It uses a verifiable form of erasure coding to disseminate data such that it can be retrieved under honest majority assumptions without requiring full replication.
The specification is separated into the following sections:
- Client: Captures the user facing API, describes how rsema1d is used, how the data is diseminated, and how the user can manage their accounts and pay for fibre blobs.
- Server: Captures the API for storing user data, verifying correct construction and valid payment.
- SDK Fibre Module: Specifies how the state machine handles payment, verifyig validator signatures and deducting from the escrow account.
- Encoding: Specifies the encoding format of rows and the format of the shares in the original data square.
- SDK Registry Module: Stores a key value list of validator addresses to their respective Fibre DA provider addresses.
For specification of the rsema1d codec refer to the pkg/rsema1d SPEC and README
Fibre Client
This document describes the Fibre client as implemented in the fibre package. It is a v0 shard upload/download client backed by a celestia-app state client and validator-operated Fibre servers.
0) Glossary
- Fibre server / FSP: validator-operated gRPC service that stores and serves blob shards.
- State client: client dependency used to fetch chain ID, validator sets, validator Fibre hosts, and payment-promise validation state.
- Blob: encoded data plus a small v0 header, Reed-Solomon parity rows, row proofs, RLC vector, and commitment.
- Commitment: 32-byte rsema1d commitment over the row root and RLC root.
- BlobID: 33 bytes:
blob_version || commitment. - PaymentPromise (PP): promise signed by the escrow owner and endorsed by validators after successful shard upload.
- ShardMap: deterministic mapping from
(commitment, validator set)to row indices per validator.
1) Construction & Config
The client is constructed with a Cosmos SDK keyring and ClientConfig.
func NewClient(kr keyring.Keyring, cfg ClientConfig) (*Client, error)
The configured key must exist in the keyring. Start(ctx) must be called before Upload, Download, or package-level Put.
client, err := fibre.NewClient(kr, fibre.DefaultClientConfig())
if err != nil {
return err
}
if err := client.Start(ctx); err != nil {
return err
}
defer client.Stop(ctx)
ClientConfig
type ClientConfig struct {
DefaultKeyName string
StateAddress string
SafetyThreshold cmtmath.Fraction
LivenessThreshold cmtmath.Fraction
MinRowsPerValidator int
MaxMessageSize int
RPCTimeout time.Duration
StateClientFn func() (state.Client, error)
NewClientFn fibregrpc.NewClientFn
Log *slog.Logger
Tracer trace.Tracer
Meter metric.Meter
Clock clock.Clock
}
Defaults come from DefaultProtocolParams:
DefaultKeyName = "default-fibre"StateAddress = "127.0.0.1:9090"SafetyThreshold = 2/3LivenessThreshold = 1/3RPCTimeout = 15sMaxBlobSize = 128 MiB- original rows
K = 4096 - total rows
K + N = 16384 - supported blob version:
0
If StateClientFn is nil, the client builds a gRPC app state client from StateAddress. If NewClientFn is nil, the client builds Fibre gRPC clients from validator hosts returned by the state client's host registry.
There are no send_workers or read_workers options in the current implementation. Upload starts one goroutine per assigned validator. Download dynamically starts validator requests until enough rows are in flight or retrieved.
2) Public API
Client Lifecycle
func (c *Client) Start(ctx context.Context) error
func (c *Client) Stop(ctx context.Context) error
func (c *Client) Await()
func (c *Client) ChainID() string
Stop marks the client closed, waits for in-flight upload/download work unless its context is canceled, and closes cached Fibre gRPC connections. Await waits for upload/download goroutines without closing the client.
Blob API
func NewBlob(data []byte, cfg BlobConfig) (*Blob, error)
func DefaultBlobConfigV0() BlobConfig
func (b *Blob) ID() BlobID
func (b *Blob) Data() []byte
func (b *Blob) DataSize() int
func (b *Blob) UploadSize() int
func (b *Blob) RowSize() int
func (b *Blob) Free()
NewBlob requires non-empty data. It returns ErrBlobTooLarge if len(data) exceeds BlobConfig.MaxDataSize (128 MiB - 5 for the default v0 header). The returned blob owns pooled storage and must be released with Free.
Upload
type UploadOption func(*uploadOptions)
func WithKeyName(keyName string) UploadOption
func WithAwaitAllSignatures() UploadOption
func (c *Client) Upload(
ctx context.Context,
ns share.Namespace,
blob *Blob,
opts ...UploadOption,
) (SignedPaymentPromise, error)
Upload signs a payment promise with the configured key, uploads assigned row shards to validators, verifies validator signatures, and returns a SignedPaymentPromise.
By default, Upload returns after the safety threshold by voting power is reached. Remaining validator uploads continue in background and are tracked by Await/Stop. WithAwaitAllSignatures changes the threshold to all validator voting power and waits for all successful signatures.
type SignedPaymentPromise struct {
*PaymentPromise
ValidatorSignatures [][]byte
}
Put
type PutResult struct {
BlobID BlobID
ValidatorSignatures [][]byte
TTL time.Time
TxHash string
Height uint64
}
func Put(
ctx context.Context,
c *Client,
txClient *user.TxClient,
ns share.Namespace,
data []byte,
) (PutResult, error)
Put is a package-level convenience helper. It creates a v0 blob, calls Client.Upload to upload assigned shards to validators and collect validator signatures, builds MsgPayForFibre, broadcasts it through the supplied user.TxClient, and waits for transaction confirmation.
Put does not use a DFSP relay client. The caller supplies the transaction client, so transaction endpoint selection, account configuration, fees, fee grants, and signing setup are determined by that user.TxClient. Put submits one MsgPayForFibre for the blob; callers that need batching or custom transaction flow should call Client.Upload directly and submit payments themselves. TTL is currently present in PutResult but is not populated.
Download
type DownloadOption func(*downloadOptions)
func WithHeight(height uint64) DownloadOption
func (c *Client) Download(
ctx context.Context,
id BlobID,
opts ...DownloadOption,
) (*Blob, error)
Download fetches and reconstructs a blob by BlobID. If WithHeight is provided, the client uses the validator set at that height; otherwise it uses the current head validator set. The returned blob owns pooled storage and must be released with Free.
The current API does not expose Get(ctx, namespace, commitment) ([]byte, error). Callers use Download(ctx, NewBlobID(version, commitment)) and then read blob.Data().
3) Payment Promise and Sign Bytes
The implemented PaymentPromise is v0-oriented and uses a secp256k1 public key to identify the escrow owner.
type PaymentPromise struct {
SignerKey *secp256k1.PubKey
ChainID string
Namespace share.Namespace
UploadSize uint32
BlobVersion uint32
Commitment Commitment
CreationTimestamp time.Time
Signature []byte
Height uint64
}
The protobuf form is:
message PaymentPromise {
string chain_id = 1;
int64 height = 2;
bytes namespace = 3;
uint32 blob_size = 4;
uint32 blob_version = 5;
bytes commitment = 6;
google.protobuf.Timestamp creation_timestamp = 7;
cosmos.crypto.secp256k1.PubKey signer_public_key = 8;
bytes signature = 9;
}
The signed payload is:
stripped =
signer_public_key_compressed_33 ||
namespace_29 ||
upload_size_u32be ||
commitment_32 ||
blob_version_u32be ||
height_u64be ||
creation_timestamp_go_binary_utc
SignBytes = CometBFT RawBytesMessageSignBytes(
chain_id,
"fibre/pp:v0",
stripped,
)
The escrow-owner signature is a 64-byte secp256k1 signature over SignBytes. Validator signatures are ed25519 signatures over the same SignBytes.
PaymentPromise.Hash() is:
SHA256(SignBytes || escrow_owner_signature)
4) Blob Encoding
Only blob version 0 is supported.
The encoded data starts with a five-byte header:
version_u8 || original_data_size_u32be
Rows are produced with rsema1d. Default protocol parameters:
- original rows:
4096 - parity rows:
12288 - total rows:
16384 - encoding ratio:
0.25 - maximum blob size, including header:
128 MiB - minimum row-size alignment:
64bytes
UploadSize is the padded original-row size only:
UploadSize = row_size * original_rows
It excludes parity rows but includes padding and the v0 header.
5) Assignment
validator.Set.Assign maps row indices to validators using voting power and the configured liveness threshold.
Inputs:
commitmenttotalRowsoriginalRowsminRowslivenessThreshold- validator set at the payment promise height
For each validator:
rows = ceil(originalRows * validator_power * liveness_denominator /
(total_voting_power * liveness_numerator))
rows = min(max(rows, minRows), originalRows)
Then:
- Seed a ChaCha8 RNG with the commitment.
- Shuffle all row indices
0..totalRows-1with Fisher-Yates. - Walk validators in CometBFT validator-set order.
- Give each validator the next
rowsshuffled row indices. - If the sum of assigned rows exceeds
totalRows, wrap around modulototalRows, which can assign the same row to multiple validators.
This is not an equal, non-overlapping permutation assignment. Overlap can occur when minimum-row guarantees over-assign rows.
6) State Client
The client depends on state.Client:
type Client interface {
validator.SetGetter
validator.HostRegistry
ChainID() string
VerifyPromise(context.Context, *types.PaymentPromise) (VerifiedPromise, error)
Start(context.Context) error
Stop(context.Context) error
}
The default implementation is the gRPC AppClient. On Start, it detects the chain ID from the app node and pulls validator Fibre provider hosts from x/valaddr.
Validator sets are fetched through CometBFT's gRPC Block API:
Head(ctx) (validator.Set, error)
GetByHeight(ctx, height uint64) (validator.Set, error)
There is no embedded light-node-backed client constructor in the current implementation.
7) gRPC Transport
The implemented Fibre service is shard-oriented:
message BlobRow {
uint32 index = 1;
bytes data = 2;
repeated bytes proof = 3;
}
message BlobShard {
repeated BlobRow rows = 1;
bytes rlcs = 2;
}
message UploadShardRequest {
PaymentPromise promise = 1;
BlobShard shard = 2;
}
message UploadShardResponse {
bytes validator_signature = 1;
}
message DownloadShardRequest {
bytes blob_id = 1;
}
message DownloadShardResponse {
BlobShard shard = 1;
}
service Fibre {
rpc UploadShard(UploadShardRequest) returns (UploadShardResponse);
rpc DownloadShard(DownloadShardRequest) returns (DownloadShardResponse);
}
BlobShard.rlcs contains the serialized full original-row RLC vector, not only coefficients for the returned rows.
The default Fibre gRPC client resolves a validator host from the state client's host registry and uses TLS with validator consensus-key identity verification.
8) Upload Flow
- Require
Startto have completed and the client not to be closed. - Retain the blob's pooled storage for the upload lifetime.
- Fetch the current validator set with
state.Head(ctx). - Build and sign a
PaymentPromiseusing the selected keyring key. - Compute
PaymentPromise.Hash()for logging/storage identity. - Compute the
ShardMapfrom the blob commitment and validator set. - Build one
UploadShardRequestenvelope per validator with the shared promise and serialized RLC vector. - Start one goroutine per validator.
- For each validator, build row data and proofs for its assigned row indices, call
UploadShardwithRPCTimeout, parse the validator signature, and add it to theSignatureSet. - Return when all validators have responded or the configured voting-power threshold is reached.
- Return
SignedPaymentPromise.
Signature collection currently enforces voting-power threshold only. It does not enforce a separate count threshold.
9) Put Flow
Put is a convenience wrapper around upload plus app transaction submission:
- Create a v0
Blobfromdata. - Call
Client.UploadusingWithKeyName(txClient.DefaultAccountName())to upload assigned shards to validators and collect validator signatures. - Convert the signed promise to proto.
- Build
x/fibreMsgPayForFibrewith validator signatures. - Broadcast through
txClient.BroadcastTx. - Wait for inclusion with
txClient.ConfirmTx. - Return
PutResult.
The implementation does not submit PFF through a Fibre payment relay service and does not implement DFSP fallback.
10) Download Flow
- Require
Startto have completed and the client not to be closed. - Validate
BlobID. - Fetch a validator set:
GetByHeight(ctx, height)whenWithHeight(height)is used.Head(ctx)otherwise.
- Select validators with
validator.Set.Select, shuffled by stake for load balancing. - Start download workers while the reconstructor still wants rows and row reservations are available.
- Each worker calls
DownloadShardwithRPCTimeout. - Parse rows, row proofs, and RLC vector from
BlobShard. - Add the shard to the
rsema1d.Reconstructor, which verifies proofs and the commitment/RLC relationship. - Stop dispatching after enough unique rows are collected or all selected validators have been tried.
- Reconstruct and decode the v0 blob header.
- Return a
Blob.
RLC verification is for client-side recovery. An attacker can publish a commitment built from tampered rows, so Merkle proofs still pass. But those rows may not be a valid Reed-Solomon encoding. RLC lets the downloader spot the bad rows, skip them, and recover from enough honest rows. It does not prevent a bad commitment from being accepted on-chain if enough validators sign it; punishment or banning is separate.
Note: The on-chain commitment in this attack is the tampered one, so it differs from the commitment for the correctly encoded data.
Errors are classified as:
ErrNotFound: no rows were retrieved.ErrNotEnoughShards: some rows were retrieved, but not enough to reconstruct.- reconstruction/verification/decode errors for invalid shards or invalid data.
- context cancellation/deadline errors from the caller or per-RPC timeout.
11) Account and Escrow APIs
The Fibre client package does not currently expose Account() or an AccountClient.
Escrow state and transactions are available through the app's x/fibre query and msg services:
Query.EscrowAccountQuery.WithdrawalsMsg.DepositToEscrowMsg.RequestWithdrawalMsg.PayForFibreMsg.PaymentPromiseTimeout
Callers that need deposits, withdrawals, escrow queries, or PFF transaction submission use the normal app gRPC query clients and transaction clients.
Escrow ledger accounting safety
When escrow auto-funding is enabled, each signer has a client-side ledger holding a single number, balance: the on-chain escrow balance minus the funds already committed to signed-but-not-yet-settled promises. balance is seeded once from chain (Query.EscrowAccount) on first use.
An upload is admitted only when balance covers its payment, at which point balance is decremented. The decrement is credited back only if the upload fails before its promise is signed — once signed, the funds are committed (the Msg.PayForFibre settlement, or Msg.PaymentPromiseTimeout if the PFF never lands, debits the escrow on chain regardless of this client), so the decrement is final. When balance dips below LowWatermark, a background deposit (Msg.DepositToEscrow, single-flighted) tops it up to HighWatermark, applied as an additive delta once confirmed.
The safety invariant is that balance is never overstated: it is only ever credited by a real confirmed deposit or by an abort-before-sign (whose funds were never committed), never by a phantom amount. Because no chain re-read overwrites balance during operation, the additive deposit delta can never double-count a concurrent reconcile, so the additive is unconditionally correct. A never-overstated balance means concurrent uploads can never collectively overcommit the escrow.
The trade-off is one-sided and deliberate: a long-running, never-idle client cannot re-anchor balance to on-chain ground truth, so it may understate over time (from aborted-before-sign uploads and promises that expire without a timeout settlement). Understating only refuses budget or tops up slightly more often than strictly needed — the excess stays in the escrow and is withdrawable — it never overcommits.
Because the ledger is in-memory only, a client that restarts loses balance and re-seeds from chain. Query.EscrowAccount reports the on-chain AvailableBalance, which does not subtract promises the crashed client had signed but that had not yet settled — so a naive re-seed would overstate balance and could over-sign. EscrowConfig.StartupGracePeriod guards against this: within that window after the ledger starts it seeds nothing, admits nothing, and deposits nothing, and waitForBudget fails fast with an explicit error. By the time the window passes, any promise signed before the crash has settled or timed out on chain, so the first seed is exact. It is disabled by default (seed immediately, preserving the behavior above); operators who require crash-safety set it to at least the chain's PaymentPromiseTimeout. The alternative — durable local persistence of balance — would remove the startup window entirely at the cost of a synchronous disk write on the signing hot path, and is intentionally out of scope here.
12) Errors
Important client-side errors include:
ErrClientClosedErrKeyNotFoundErrBlobTooLargeErrNotFoundErrNotEnoughShardsvalidator.NotEnoughSignaturesError
Other errors are returned as wrapped errors from keyring operations, state lookups, gRPC calls, row proof generation, reconstruction, decoding, or transaction broadcasting/confirmation.
There is no dedicated client error mapping for insufficient escrow balance, invalid namespace, PFF submission, or RLC mismatch.
13) Metrics
The current client records OpenTelemetry metrics for:
- upload in-flight count and duration
- uploaded padded bytes, original data bytes, and network bytes
- validator signatures collected
- per-validator upload duration and RPC latency
- download in-flight count, duration, and bytes
- per-validator download duration and RPC latency
It does not currently expose separate metrics for encode latency, chosen row size, quorum time, PFF submission/inclusion, balance cache age, or insufficient proof handling.
Fibre Server
This document describes the Fibre server implemented by the fibre.Server type. The server is a validator-operated gRPC service that accepts assigned blob shards, verifies payment promises and row proofs, stores shards locally until the payment promise expires, signs the payment promise with the validator consensus key, and serves stored shards back to download clients.
Public gRPC API
The implemented data-plane service is celestia.fibre.v1.Fibre:
service Fibre {
rpc UploadShard(UploadShardRequest) returns (UploadShardResponse);
rpc DownloadShard(DownloadShardRequest) returns (DownloadShardResponse);
}
message BlobRow {
uint32 index = 1;
bytes data = 2;
repeated bytes proof = 3;
}
message BlobShard {
repeated BlobRow rows = 1;
bytes rlcs = 2;
}
message UploadShardRequest {
PaymentPromise promise = 1;
BlobShard shard = 2;
}
message UploadShardResponse {
bytes validator_signature = 1;
}
message DownloadShardRequest {
bytes blob_id = 1;
}
message DownloadShardResponse {
BlobShard shard = 1;
}
There is no Fibre server FibreAccount API and no server-side PaymentProcessor relay API in the current implementation. Escrow account operations, MsgPayForFibre, and timeout settlement are handled through the normal app query and transaction clients.
PaymentPromise
The server uses the celestia.fibre.v1.PaymentPromise protobuf from x/fibre:
message PaymentPromise {
string chain_id = 1;
int64 height = 2;
bytes namespace = 3;
uint32 blob_size = 4;
uint32 blob_version = 5;
bytes commitment = 6;
google.protobuf.Timestamp creation_timestamp = 7;
cosmos.crypto.secp256k1.PubKey signer_public_key = 8;
bytes signature = 9;
}
The internal fibre.PaymentPromise treats signer_public_key as the escrow-owner secp256k1 public key. blob_size is the padded upload size used by Fibre, not the raw user payload size. The supported blob version is currently 0.
Sign Bytes
Both the escrow owner and validators sign the same CometBFT raw-bytes domain:
SignBytes = RawBytesMessageSignBytes(chain_id, "fibre/pp:v0", stripped)
stripped =
signer_public_key_compressed_33 ||
namespace_29 ||
upload_size_u32be ||
commitment_32 ||
blob_version_u32be ||
height_u64be ||
creation_timestamp_utc_go_binary
PaymentPromise.Hash() is SHA256(SignBytes || escrow_owner_signature). Validator signatures are produced with the validator consensus signer via PrivValidator.SignRawBytes(chain_id, "fibre/pp:v0", stripped) and must be ed25519 signature length.
Construction And Configuration
NewServer validates ServerConfig, constructs the app state client, creates metrics, allocates the verifier pool, and binds the gRPC listener.
type ServerConfig struct {
AppGRPCAddress string
ServerListenAddress string
SignerGRPCAddress string
UploadVerifyWorkers int
StoreConfig
LivenessThreshold cmtmath.Fraction
MinRowsPerValidator int
MaxMessageSize int
StoreFn func(StoreConfig) (*Store, error)
StateClientFn func() (state.Client, error)
SignerFn func(chainID string) (core.PrivValidator, error)
Log *slog.Logger
Tracer trace.Tracer
Meter metric.Meter
}
Defaults:
app_grpc_address = "127.0.0.1:9090"
server_listen_address = "0.0.0.0:7980"
signer_grpc_address = "127.0.0.1:26669"
upload_verify_workers = runtime.GOMAXPROCS(0)
StoreConfig.Path is not a TOML field; the standalone fibre start command sets it from --home. The default state client is a gRPC app client connected to AppGRPCAddress. The default signer is a PrivValidatorAPI gRPC client connected to SignerGRPCAddress. Both app-node gRPC and signer gRPC use insecure local transport and are expected to be loopback or otherwise protected.
Lifecycle
Server.Start starts the state client first, detects the chain ID, creates the signer, builds a TLS certificate endorsed by the validator consensus key, registers the Fibre gRPC service with TLS 1.3 credentials and max send/receive message sizes, opens the store, starts the prune loop, and starts serving gRPC in the background.
Server.Stop cancels the prune loop, stops the gRPC server, closes the signer if it implements io.Closer, closes the store, and stops the state client.
Transport Security
The Fibre server-to-client gRPC link is TLS-only. On startup the server generates an ephemeral TLS keypair and uses the validator consensus signer to endorse that TLS public key. Clients verify the presented TLS key against the expected validator consensus public key and chain ID. There is no client certificate requirement and no mTLS. DownloadShard is public to any reachable client that can complete the server-authenticated TLS handshake.
State Client
The server depends on state.Client for chain ID, validator sets, validator host lookup, and payment-promise state validation. The default implementation is fibre/internal/grpc.AppClient, which uses app-node gRPC. Validator sets are fetched through the CometBFT Block API ValidatorSet endpoint. Payment promises are checked with the app x/fibre ValidatePaymentPromise query, which returns the expiration time used for local pruning.
UploadShard Flow
UploadShard performs the following work:
- Convert the protobuf payment promise into the internal
fibre.PaymentPromise. - Check that
promise.chain_idmatches the connected app chain ID. - Check that
promise.blob_versionis supported. - Run stateless promise validation: signer public key exists and is 33 bytes, chain ID is non-empty and at most 20 bytes, upload size is positive, creation timestamp is nonzero, escrow-owner signature is 64 bytes, height is positive, and the escrow-owner secp256k1 signature verifies against
SignBytes. - Run stateful validation through the app state client. On success this returns
ExpiresAtandShardRetention(thex/fibreon-chain, governance-changeable parameter, default 4h); the server computespruneAt = max(ExpiresAt, creation_timestamp + ShardRetention), so shards are kept for at least the configured retention and are never pruned while the promise is still valid. - Compute the payment-promise hash.
- Fetch the validator set at
promise.height. - Fetch this server's validator consensus public key from the signer and find it in the validator set.
- Compute
validator.Set.Assign(promise.commitment, totalRows, originalRows, minRows, livenessThreshold). - Verify the uploaded row indices exactly match this validator's assignment by count, membership, and duplicate checks.
- Validate the shard: all rows must be present and share one nonzero row size, each row must include data and proof,
promise.blob_sizemust equalrow_size * originalRows,shard.rlcsmust unmarshal, andrsema1d.Verifier.Verifymust accept the commitment, row proofs, and RLC vector. - Store the promise and shard.
- Sign the payment promise with the validator signer and return the validator signature.
The server stores before signing. A successful validator signature means the server accepted and stored the shard.
Assignment
Assignment is not a base/remainder split over a non-overlapping permutation. The implementation computes rows per validator from voting power and the liveness threshold:
rows = ceil(originalRows * votingPower * livenessThreshold.denominator / (totalVotingPower * livenessThreshold.numerator))
rows = min(max(rows, minRows), originalRows)
The row indices 0..totalRows-1 are shuffled with a ChaCha8 RNG seeded by the commitment. Validators are then walked in CometBFT validator-set order and assigned the next rows shuffled indices. If the total assigned rows exceed totalRows, assignment wraps modulo totalRows, so the same row may be assigned to multiple validators.
DownloadShard Flow
DownloadShard accepts a 33-byte BlobID (blob_version || commitment), validates the blob ID and supported blob version, looks up a stored shard by commitment, and returns the first matching stored BlobShard. If there are multiple promises for the same commitment, the store returns one deterministic matching shard rather than concatenating all rows for all promises. Missing data returns gRPC NotFound.
Storage
The store uses Pebble for metadata and flat files for bulk shard payloads. The layout under StoreConfig.Path is:
shards/<commitment-hex>-<promise-hash-hex> finalized shard payload
staging/<random> temporary in-flight write
Pebble metadata keys are:
/pp/<promise-hash-hex> protobuf PaymentPromise
/shard/<commitment-hex>/<promise-hash-hex> shard marker
/prune/<YYYYMMDDHHmm>/<commitment>/<hash> prune index
Store.Put writes the shard to a random staging file, writes metadata, then renames the staging file to the canonical shard file. Puts for the same commitment but different payment promises are stored independently by promise hash. Store.Get(commitment) iterates /shard/<commitment>/ and returns the first readable shard file. If it finds an orphan marker whose shard file is missing, it deletes the marker lazily. Store.PruneBefore iterates the ordered /prune/ index and deletes shard files, shard markers, payment promises, and prune entries whose prune timestamp is older than the cutoff.
Pruning
The only background worker in the server is the prune loop. It runs once per minute and calls Store.PruneBefore(time.Now()), deleting shards whose pruneAt has passed. pruneAt is max(ExpiresAt, creation_timestamp + ShardRetention), where ShardRetention is the x/fibre on-chain, governance-changeable parameter (default 4h) independent of the chain's PaymentPromiseTimeout. There is no block subscriber, no local unprocessed-to-processed promotion, and no timeout scanner that submits MsgPaymentPromiseTimeout.
Error Mapping
Current gRPC status behavior is intentionally simple:
| RPC | Condition | Status |
|---|---|---|
UploadShard | payment promise conversion, chain ID, blob version, stateless validation, or stateful validation fails | InvalidArgument |
UploadShard | assignment verification fails | InvalidArgument |
UploadShard | row, proof, RLC, upload-size, or commitment verification fails | InvalidArgument |
UploadShard | store write or validator signing fails | Internal |
DownloadShard | invalid blob ID or unsupported blob version | InvalidArgument |
DownloadShard | no shard found for commitment | NotFound |
DownloadShard | store read failure | Internal |
The implementation does not currently return FailedPrecondition, PermissionDenied, AlreadyExists, or ResourceExhausted for the cases described by older target designs, and responses do not include machine-readable error details or backoff hints.
Concurrency And DoS Controls
The server does not implement per-peer token buckets, throughput caps, request backoff hints, or explicit upload/download RPC concurrency limits. Upload verification concurrency is bounded by UploadVerifyWorkers, which is the size of the pooled rsema1d.Verifier channel. gRPC receive/send message size is bounded by MaxMessageSize from protocol params.
Metrics
The server records OpenTelemetry metrics for:
fibre.server.upload_shard.in_flightfibre.server.upload_shard.durationfibre.server.upload_shard.bytesfibre.server.download_shard.in_flightfibre.server.download_shard.durationfibre.server.download_shard.bytesfibre.server.store.put.durationfibre.server.store.get.durationfibre.server.sign.durationfibre.server.prune.entriesfibre.server.prune.duration
Fibre SDK Module x/fibre
Abstract
The x/fibre module is the escrow and settlement module for Fibre payment promises. Users deposit funds into module-controlled escrow accounts, sign off-chain PaymentPromise values for specific blobs, and later settle those promises on-chain either through MsgPayForFibre with validator signatures or through MsgPaymentPromiseTimeout after the promise expires.
The module manages escrow balances, delayed withdrawals, payment deduction, processed-payment replay protection, stateful payment-promise validation, events, queries, genesis state, and module parameters. It does not receive blob bytes and it does not directly build the data square; when the fibre app path is enabled, the app square builder recognizes valid standalone MsgPayForFibre transactions and synthesizes the corresponding Fibre system blob for square inclusion.
Flow
- The escrow owner funds an escrow account with
MsgDepositToEscrow. - The escrow owner creates a signed
PaymentPromiseoff-chain. The promise names the chain, validator-set height, namespace, blob size, blob version, commitment, creation timestamp, escrow-owner secp256k1 public key, and secp256k1 signature. - A validator or Fibre server performs stateless validation locally and can call
Query/ValidatePaymentPromisefor stateful validation. The query checks freshness, expiry, height window, replay status, escrow existence, and total escrow balance; it intentionally does not verify the signature or field format. - A normal settlement submits
MsgPayForFibrecontaining exactly one payment promise and validator signatures. The message server validates the promise, verifies enough validator voting power signed the promise sign bytes at the promise height, deducts the payment from escrow, records the promise hash as processed, and emitsEventPayForFibre. - A timeout settlement submits
MsgPaymentPromiseTimeoutaftercreation_timestamp + payment_promise_timeout. The message server validates the promise and state, skips normal expiry and height-window checks, deducts the same payment amount from escrow, records the promise hash as processed, and emitsEventPaymentPromiseTimeout. - At the beginning of each block, the module processes available withdrawals first and then prunes processed payments outside the retention window.
Fibre Blob Settlement
sequenceDiagram
participant C as Escrow owner / client
participant FS as Fibre server / validator
participant Q as x/fibre query service
participant A as App proposal path
participant M as x/fibre msg server
participant P as Timeout processor
C->>M: MsgDepositToEscrow(amount)
M->>M: Create or update escrow account
C->>C: Create v0 blob, commitment, and signed PaymentPromise
loop Assigned validators
C->>FS: UploadShard(PaymentPromise, assigned rows, proofs, RLC)
FS->>FS: Stateless promise validation and assignment check
FS->>Q: ValidatePaymentPromise(PaymentPromise)
Q-->>FS: expiration_time
FS->>FS: Store shard until expiration
FS-->>C: Validator signature over PaymentPromise sign bytes
end
C->>A: Tx containing one MsgPayForFibre
A->>A: Append PFF tx and synthesize Fibre system blob
A->>M: Execute MsgPayForFibre
M->>M: Validate promise and state
M->>M: Verify validator signatures by voting power
M->>M: Deduct escrow and record processed payment
M-->>C: EventPayForFibre
P->>M: MsgPaymentPromiseTimeout(PaymentPromise)
M->>M: Timeout validation, escrow deduction, processed-payment record
M-->>P: EventPaymentPromiseTimeout
Note over M,A: Timeout settlement does not synthesize a Fibre system blob
ValidatePaymentPromise is a stateful query. It checks freshness, expiry,
height window, replay status, escrow existence, and total escrow balance. The
Fibre server and MsgPayForFibre handler perform stateless validation and
signature verification outside that query.
Withdrawal Processing
sequenceDiagram
participant C as Escrow owner
participant M as x/fibre msg server
participant B as BeginBlocker
participant Bank as Bank keeper
C->>M: MsgRequestWithdrawal(amount)
M->>M: Check escrow and available_balance
M->>M: Subtract amount from available_balance
M->>M: Store withdrawal by signer and available time
Note over M: Total balance remains escrowed until BeginBlock
B->>M: processAvailableWithdrawals()
M->>M: Iterate withdrawals available at block time
M->>M: Subtract amount from total balance and store escrow
M->>Bank: Send coins from fibre module account to signer
alt bank send succeeds
M->>M: Delete withdrawal from both indexes
M-->>C: EventWithdrawFromEscrowExecuted
else bank send fails
M->>M: Log error and leave withdrawal record
end
B->>M: pruneProcessedPayments()
M->>M: Delete replay records older than retention window
State
The module store key is fibre. Module params are stored under the raw key params. The other state objects use byte prefixes from x/fibre/types/keys.go: escrow accounts use 0x02, withdrawals-by-signer use 0x03, withdrawals-by-available-time use 0x04, processed-payments-by-hash use 0x05, and processed-payments-by-time use 0x06.
EscrowAccount
An escrow account is keyed by the escrow signer address with 0x02 || signer. balance is the total amount held in the module account for that signer and available_balance is the amount that has not been reserved by pending withdrawal requests.
message EscrowAccount {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin balance = 2 [(gogoproto.nullable) = false];
cosmos.base.v1beta1.Coin available_balance = 3 [(gogoproto.nullable) = false];
}
Payments are validated against and deducted from total balance, not only available_balance. If a payment spends funds that are currently locked in pending withdrawals, the module reduces or deletes those pending withdrawals so that the escrow state remains consistent.
Withdrawal
Withdrawal requests are stored in two indexes. The signer index key is 0x03 || signer || "/" || sdk.FormatTimeBytes(requested_timestamp) and the availability index key is 0x04 || sdk.FormatTimeBytes(available_timestamp) || "/" || signer.
message Withdrawal {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin amount = 2 [(gogoproto.nullable) = false];
google.protobuf.Timestamp requested_timestamp = 3 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
google.protobuf.Timestamp available_timestamp = 4 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
}
MsgRequestWithdrawal immediately subtracts the amount from available_balance and records a withdrawal with available_timestamp = block_time + withdrawal_delay. The total escrow balance is not reduced until BeginBlock processes the withdrawal.
ProcessedPayment
Processed payments are stored for replay protection and pruning. The hash index key is 0x05 || payment_promise_hash and the time index key is 0x06 || sdk.FormatTimeBytes(processed_at) || "/" || payment_promise_hash.
message ProcessedPayment {
bytes payment_promise_hash = 1;
google.protobuf.Timestamp processed_at = 2 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
}
MsgPayForFibre and MsgPaymentPromiseTimeout both compute the internal payment-promise hash and store a ProcessedPayment at the current block time. BeginBlock prunes processed payments whose processed_at is outside the payment_promise_retention_window.
GenesisState
Genesis contains params, escrow accounts, withdrawals, and processed payments.
message GenesisState {
Params params = 1 [(gogoproto.nullable) = false];
repeated EscrowAccount escrow_accounts = 2 [(gogoproto.nullable) = false];
repeated Withdrawal withdrawals = 3 [(gogoproto.nullable) = false];
repeated ProcessedPayment processed_payments = 4 [(gogoproto.nullable) = false];
}
Genesis validation checks params, rejects empty or duplicate escrow signers, requires escrow balances to be valid with available_balance <= balance, requires withdrawals to have a signer, positive valid amount, and nonzero requested timestamp, and requires processed payments to have a non-empty unique hash and nonzero processed_at.
PaymentPromise
PaymentPromise is the on-chain protobuf representation of an off-chain promise signed by the escrow owner. The signer public key is a concrete cosmos.crypto.secp256k1.PubKey, not an Any.
message PaymentPromise {
string chain_id = 1;
int64 height = 2;
bytes namespace = 3;
uint32 blob_size = 4;
uint32 blob_version = 5;
bytes commitment = 6;
google.protobuf.Timestamp creation_timestamp = 7 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
cosmos.crypto.secp256k1.PubKey signer_public_key = 8 [(gogoproto.nullable) = false];
bytes signature = 9;
}
Sign Bytes And Hash
The internal fibre.PaymentPromise canonical payload bytes are:
stripped_sign_bytes =
signer_public_key_compressed_33 ||
namespace_29 ||
big_endian_u32(blob_size) ||
commitment_32 ||
big_endian_u32(blob_version) ||
big_endian_u64(height) ||
creation_timestamp.UTC().MarshalBinary()
The bytes signed by the escrow owner and by validators are core.RawBytesMessageSignBytes(chain_id, "fibre/pp:v0", stripped_sign_bytes). The chain ID and "fibre/pp:v0" prefix are applied by CometBFT raw-bytes domain separation and are not raw-concatenated into stripped_sign_bytes.
The payment-promise hash used for replay protection is:
SHA256(sign_bytes || signature)
The internal Hash method requires a non-empty signature before computing this hash.
Stateless Validation
The SDK PaymentPromise.ValidateBasic checks that chain_id is non-empty, namespace is exactly 29 bytes and valid for blob use, blob_size is positive, commitment is exactly 32 bytes, blob_version is 0, height is positive, creation_timestamp is nonzero, signer_public_key.key is exactly 33 bytes, and signature is non-empty.
The message handlers also convert the protobuf value to fibre.PaymentPromise and call the internal Validate method. Internal validation requires a non-nil 33-byte secp256k1 signer key, non-empty chain ID no longer than 20 bytes, positive upload size, nonzero creation timestamp, a 64-byte compact secp256k1 signature, positive height, and a valid signature over the canonical sign bytes.
Stateful Validation
ValidatePaymentPromiseStateful checks the current chain state and returns the promise expiration time on success. Normal validation requires creation_timestamp to be strictly after block_time - withdrawal_delay, rejects promises at or after creation_timestamp + payment_promise_timeout, rejects promises more than payment_promise_height_window blocks behind the current height, rejects promises more than one block ahead of the current height, rejects already processed promises, requires an escrow account for sdk.AccAddress(signer_public_key.Address()), and requires total escrow balance to cover the payment amount.
ValidatePaymentPromiseStatefulForTimeout performs the same checks except that it skips the normal expiration check and the normal height-window checks. Timeout processing still rejects promises whose creation timestamp is older than block_time - withdrawal_delay, still rejects already processed promises, still requires an escrow account, and still requires total escrow balance to cover the payment amount.
Payment Amount
MsgPayForFibre and MsgPaymentPromiseTimeout both charge the same amount. The implementation estimates gas with a standalone formula and converts that gas amount to a coin in appconsts.BondDenom (utia).
gas = 650000 + 45000 * ceil(blob_size / 262144)
amount = gas utia
If EstimateGasForPayForFibre is called with blob_size == 0, it returns only the fixed cost of 650000, although valid payment promises require a positive blob size. This payment formula does not use gas_per_blob_byte or GasPerCelestiaByte; gas_per_blob_byte still exists as a positive module parameter but is currently not part of Fibre payment calculation.
Messages
MsgDepositToEscrow
message MsgDepositToEscrow {
option (cosmos.msg.v1.signer) = "signer";
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin amount = 2 [(gogoproto.nullable) = false];
}
ValidateBasic requires a valid bech32 signer address and a valid positive coin. The handler gets or creates the escrow account, sends the coin from the signer account to the fibre module account, adds the amount to both balance and available_balance, stores the escrow account, and emits EventDepositToEscrow.
MsgRequestWithdrawal
message MsgRequestWithdrawal {
option (cosmos.msg.v1.signer) = "signer";
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin amount = 2 [(gogoproto.nullable) = false];
}
ValidateBasic requires a valid bech32 signer address and a valid positive coin. The handler requires an existing escrow account, requires available_balance >= amount, rejects a key collision with an existing withdrawal at the current block timestamp, stores a withdrawal with requested_timestamp = block_time and available_timestamp = block_time + withdrawal_delay, subtracts the amount from available_balance, and emits EventWithdrawFromEscrowRequest.
MsgPayForFibre
message MsgPayForFibre {
option (cosmos.msg.v1.signer) = "signer";
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
PaymentPromise payment_promise = 2 [(gogoproto.nullable) = false];
repeated bytes validator_signatures = 3;
}
ValidateBasic requires a valid transaction signer, a valid payment promise by PaymentPromise.ValidateBasic, and at least one validator signature. The handler converts the promise to the internal Fibre type, verifies the internal stateless validation and escrow-owner secp256k1 signature, runs normal stateful validation, verifies validator signatures, hashes the promise, derives the escrow signer from payment_promise.signer_public_key, deducts the calculated payment amount from escrow, stores the processed payment, and emits EventPayForFibre.
Validator signatures are interpreted as a slice indexed by the validator-set order at payment_promise.height. Empty signatures are skipped, non-empty signatures whose index exceeds the validator count are invalid, each non-empty signature must verify with the corresponding CometBFT ed25519 validator public key over the payment-promise sign bytes, and the only threshold enforced is collected voting power at least floor(2/3 * total_voting_power). This means exactly two thirds can pass when the integer voting power calculation allows it, for example 2 of 3 total power. The implementation does not enforce a separate validator-count threshold. EventPayForFibre.validator_count is the length of the submitted signature slice.
Payment deduction first requires total escrow balance >= payment_amount. It subtracts the full payment from total balance, subtracts min(available_balance, payment_amount) from available_balance, and if the payment uses funds that were locked in pending withdrawals, it calls ReduceWithdrawalsForPayment to delete or reduce the signer's pending withdrawals in signer-index iteration order.
Stateful Processing:
- Validate PaymentPromise
- Verify validator ed25519 signatures represent 2/3+ threshold from validator set at
promise.height(obtained via historical info query from staking module):- Each signature is verified using the validator's ed25519 public key from the validator set
- Calculate gas cost (see Payment Amount section) and deduct from both escrow balance and available_balance. The deducted amount is transferred from the fibre module account to the
fee_collectormodule account, where it is distributed to validators and delegators byx/distributionlike a regular data-availability fee (see Payment Settlement Destination). - Mark promise as processed by storing
ProcessedPaymentwithprocessed_attimestamp in both indexes:processed_payments_by_hash/{payment_promise_hash}for replay protectionprocessed_payments_by_time/{processed_at}/{payment_promise_hash}for time-ordered pruning
- Include commitment in data square
- Emit EventPayForFibre
When processing a successful MsgPayForFibre, two pieces of metadata are written to the original data square:
- The tx containing the
MsgPayForFibreis included in the reserved namespace for Fibre transactions. - A system-level blob is generated with the namespace from the PaymentPromise and the blob data is the Fibre blob commitment.
MsgPaymentPromiseTimeout
message MsgPaymentPromiseTimeout {
option (cosmos.msg.v1.signer) = "signer";
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
PaymentPromise payment_promise = 2 [(gogoproto.nullable) = false];
}
ValidateBasic requires a valid transaction signer and a valid payment promise by PaymentPromise.ValidateBasic. The signer is the processor and can be any account. The handler converts and internally validates the promise, runs timeout stateful validation, requires block_time >= creation_timestamp + payment_promise_timeout, calculates and deducts the same payment amount used by MsgPayForFibre, stores the processed payment, and emits EventPaymentPromiseTimeout. Timeout processing does not require validator signatures and does not create a data-square system blob.
MsgUpdateFibreParams
message MsgUpdateFibreParams {
option (cosmos.msg.v1.signer) = "authority";
string authority = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
Params params = 2 [(gogoproto.nullable) = false];
}
ValidateBasic requires a valid authority address and valid params. The handler requires authority == keeper.GetAuthority(), requires all params to be supplied and valid, stores the new params, and emits EventUpdateFibreParams.
Data Square Construction
The SDK module does not insert commitments or blobs into the data square. Data-square metadata is synthesized during app square construction when the fibre build path is enabled.
A valid PayForFibre transaction for square construction is a plain SDK transaction that contains exactly one MsgPayForFibre and no other messages. PrepareProposal separates these transactions from normal SDK transactions, drops mixed or multi-PFF transactions, skips transactions after MaxPayForFibreMessages, and appends accepted Fibre transactions to the square builder. ProcessProposal rejects a block if a plain SDK transaction contains multiple MsgPayForFibre messages, mixes MsgPayForFibre with other messages, or causes the block to exceed MaxPayForFibreMessages.
The current production constant is:
const MaxPayForFibreMessages = 200
tx.TryParseFibreTx parses the MsgPayForFibre, requires a present payment_promise, decodes the promise namespace, decodes the transaction signer bech32 address to raw bytes, and builds the system blob with:
share.NewV2Blob(namespace, payment_promise.blob_version, payment_promise.commitment, signer_bytes)
Therefore the synthesized system blob includes the promise namespace, blob version, commitment, and raw message signer bytes. The v2 blob payload represents the blob version and 32-byte commitment; it is not just the commitment by itself. The PayForFibre transaction bytes are encoded under the PayForFibre namespace while the synthesized system blob is appended as the associated Fibre system blob by the square builder.
- Validate PaymentPromise
- Verify
promise.creation_timestamp + payment_promise_timeout <= header_timestamp(timeout has passed) - Calculate gas cost (see Payment Amount section) and deduct from both escrow balance and available_balance. As with
MsgPayForFibre, the deducted amount is transferred from the fibre module account to thefee_collectormodule account (see Payment Settlement Destination). - Mark promise as processed by storing
ProcessedPaymentwithprocessed_attimestamp in both indexes:processed_payments_by_hash/{payment_promise_hash}for replay protectionprocessed_payments_by_time/{processed_at}/{payment_promise_hash}for time-ordered pruning
- DO NOT include commitment in data square (since no validator consensus was reached)
- Emit EventPaymentPromiseTimeout
Payment Settlement Destination
Both settlement paths (MsgPayForFibre and MsgPaymentPromiseTimeout) charge the escrow owner the gas-based payment amount. This charge is distinct from the fee paid for the settlement transaction itself: the transaction fee is paid by the broadcaster and distributed via the ante handler, whereas the escrow charge is the data-availability fee owed by the escrow owner for the Fibre blob.
The charged amount is transferred from the fibre module account to the fee_collector module account. From there it follows the standard fee pipeline in x/distribution, paying validators (proportional to stake) and their delegators, with the community tax applied. This mirrors how regular blob fees (MsgPayForBlobs) are settled, and keeps the funds from being stranded in the fibre module account.
The destination is independent of which validators signed the PaymentPromise. This is required because the timeout path carries no validator signatures, so a signer-dependent destination could not settle both paths consistently.
Automatic State Transitions
BeginBlocker runs processAvailableWithdrawals first and pruneProcessedPayments second.
processAvailableWithdrawals iterates the withdrawals-by-available-time index in time order, stops when it reaches a future available_timestamp, parses the signer from the key, loads the withdrawal, loads the escrow account, subtracts the withdrawal amount from total balance, stores the escrow account, sends coins from the fibre module account to the signer account, deletes the withdrawal from both indexes after a successful send, and emits EventWithdrawFromEscrowExecuted. If key parsing, signer parsing, escrow lookup, balance sufficiency, bank send, or event emission fails, the implementation logs the error and continues; the escrow balance is stored before the bank send and the withdrawal is deleted only after a successful send.
pruneProcessedPayments computes cutoff_time = block_time - payment_promise_retention_window, iterates the processed-payments-by-time index in time order, stops when processed_at is after the cutoff, deletes each pruned processed payment from both indexes, and emits EventProcessedPaymentPruned.
Events
message EventDepositToEscrow {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin amount = 2 [(gogoproto.nullable) = false];
}
message EventWithdrawFromEscrowRequest {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin amount = 2 [(gogoproto.nullable) = false];
google.protobuf.Timestamp requested_at = 3 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
google.protobuf.Timestamp available_at = 4 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
}
message EventWithdrawFromEscrowExecuted {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
cosmos.base.v1beta1.Coin amount = 2 [(gogoproto.nullable) = false];
}
message EventPayForFibre {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
bytes namespace = 2;
bytes commitment = 3;
uint32 validator_count = 4;
}
message EventPaymentPromiseTimeout {
string processor = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
string escrow_signer = 2 [(cosmos_proto.scalar) = "cosmos.AddressString"];
bytes payment_promise_hash = 3;
}
message EventUpdateFibreParams {
string signer = 1 [(cosmos_proto.scalar) = "cosmos.AddressString"];
Params params = 2 [(gogoproto.nullable) = false];
}
message EventProcessedPaymentPruned {
bytes payment_promise_hash = 1;
google.protobuf.Timestamp processed_at = 2 [(gogoproto.nullable) = false, (gogoproto.stdtime) = true];
}
EventPayForFibre.signer is the escrow signer derived from the payment promise public key, not necessarily the transaction signer. EventPaymentPromiseTimeout.processor is the transaction signer that submitted the timeout, while escrow_signer is derived from the payment promise public key.
Queries
service Query {
rpc Params(QueryParamsRequest) returns (QueryParamsResponse) {
option (google.api.http).get = "/fibre/v1/params";
}
rpc EscrowAccount(QueryEscrowAccountRequest) returns (QueryEscrowAccountResponse) {
option (google.api.http).get = "/fibre/v1/escrow-account/{signer}";
}
rpc Withdrawals(QueryWithdrawalsRequest) returns (QueryWithdrawalsResponse) {
option (google.api.http).get = "/fibre/v1/withdrawals/{signer}";
}
rpc IsPaymentProcessed(QueryIsPaymentProcessedRequest) returns (QueryIsPaymentProcessedResponse) {
option (google.api.http).get = "/fibre/v1/is-payment-processed/{promise_hash}";
}
rpc ValidatePaymentPromise(QueryValidatePaymentPromiseRequest) returns (QueryValidatePaymentPromiseResponse) {
option (google.api.http) = {
post: "/fibre/v1/validate-payment-promise",
body: "*"
};
}
}
Params returns the current params. EscrowAccount returns an escrow account and a found bool. Withdrawals returns withdrawals for a signer; the protobuf request and response contain pagination fields, but the current query handler ignores pagination and returns all matching withdrawals with an empty pagination response. IsPaymentProcessed returns processed_at and found. ValidatePaymentPromise performs stateful validation only; callers are expected to perform stateless validation before using it, and an invalid promise is returned as a gRPC error rather than a successful response with is_valid = false.
message QueryValidatePaymentPromiseResponse {
bool is_valid = 1;
google.protobuf.Timestamp expiration_time = 2 [(gogoproto.stdtime) = true];
}
On success, ValidatePaymentPromise returns is_valid = true and expiration_time = creation_timestamp + payment_promise_timeout.
Parameters
message Params {
uint32 gas_per_blob_byte = 1 [(gogoproto.moretags) = "yaml:\"gas_per_blob_byte\""];
google.protobuf.Duration withdrawal_delay = 2 [(gogoproto.moretags) = "yaml:\"withdrawal_delay\"", (gogoproto.stdduration) = true, (gogoproto.nullable) = false];
google.protobuf.Duration payment_promise_timeout = 3 [(gogoproto.moretags) = "yaml:\"payment_promise_timeout\"", (gogoproto.stdduration) = true, (gogoproto.nullable) = false];
google.protobuf.Duration payment_promise_retention_window = 4 [(gogoproto.moretags) = "yaml:\"payment_promise_retention_window\"", (gogoproto.stdduration) = true, (gogoproto.nullable) = false];
uint64 payment_promise_height_window = 5 [(gogoproto.moretags) = "yaml:\"payment_promise_height_window\""];
}
| Parameter | Default | Validation | Current use |
|---|---|---|---|
gas_per_blob_byte | 1 | Must be nonzero | Stored and exposed as a parameter, but not used by the current PayForFibre payment formula |
withdrawal_delay | 24h | Must be positive | Sets withdrawal availability and the oldest accepted payment-promise creation time |
payment_promise_timeout | 1h | Must be positive | Defines normal promise expiration and when timeout processing becomes valid |
payment_promise_retention_window | 24h | Must be positive | Defines when processed-payment replay records are pruned |
payment_promise_height_window | 1000 | Must be nonzero | Limits how far behind the current height a normal payment promise can be |
CLI
The transaction CLI exposes:
celestia-appd tx fibre deposit-to-escrow [amount]
celestia-appd tx fibre request-withdrawal [amount]
celestia-appd tx fibre pay-for-fibre [payment-promise-json] [validator-signatures]
celestia-appd tx fibre payment-promise-timeout [payment-promise-json]
pay-for-fibre expects payment-promise-json to be a JSON representation of PaymentPromise and validator-signatures to be a comma-separated list of hex-encoded validator signatures.
The query CLI exposes:
celestia-appd query fibre params
celestia-appd query fibre escrow-account [signer]
celestia-appd query fibre withdrawals [signer]
celestia-appd query fibre is-payment-processed [payment-promise-hash]
There is currently no CLI command wrapping the ValidatePaymentPromise gRPC query.
Validator Address Registry
Abstract
The x/valaddr module lets a validator operator register the Fibre server host for its consensus validator. Fibre clients use these records to resolve the gRPC endpoint for validators selected from a validator set.
The module is wired into the app only when the fibre build tag is enabled.
Contents
Concepts
Fibre Provider Host
A Fibre provider host is the dial target for a validator-operated Fibre gRPC server. The registered value is a canonical host:port string. The host portion can be a DNS name, an IPv4 literal, or a bracketed IPv6 literal. Schemes such as http:// or dns:/// and URL paths are rejected by message validation.
The registry is keyed by validator consensus address, but registration is submitted by the validator operator address (celestiavaloper...). The message handler looks up the staking validator, derives its consensus public key, and stores the host under the derived consensus address.
The registry does not compute validator-set membership. AllFibreProviders returns all stored provider records; clients combine these records with the current validator set when selecting providers.
State
The x/valaddr module stores provider info under the module store key valaddr.
FibreProviderInfo
message FibreProviderInfo {
// host is the network address for the fibre service provider.
string host = 1;
}
Store Keys
0x01 | ValidatorConsensusAddress -> ProtocolBuffer(FibreProviderInfo): maps a validator consensus address to its Fibre provider host.
Messages
MsgSetFibreProviderInfo
Allows a validator operator to set or update Fibre provider information for its validator.
message MsgSetFibreProviderInfo {
option (cosmos.msg.v1.signer) = "signer";
// signer is the validator's operator address (celestiavaloper...).
string signer = 1 [(cosmos_proto.scalar) = "cosmos.ValidatorAddressString"];
// host is the network address for the fibre service provider.
string host = 2;
}
Validation rules:
signermust be a non-empty valid validator operator address.hostmust be non-empty and at most 100 characters.hostmust be inhost:portform.- The host part must be non-empty.
- The port must be numeric and in the range
[1, 65535]. - The normal transaction path rejects scheme-prefixed or path-bearing hosts because they do not match canonical
host:portform. - The message handler requires the validator operator address to exist in the staking keeper, derives the validator consensus address, and stores the host under that consensus address.
Events
Set Fibre Provider Info
The proto event shape is:
message EventSetFibreProviderInfo {
// validator_consensus_address is the validator consensus address (celestiavalcons...).
string validator_consensus_address = 1;
// host is the network address for the fibre service provider.
string host = 2;
}
The current message handler emits a plain SDK event:
type: set_fibre_provider_info
attributes:
validator_consensus_address = <celestiavalcons...>
host = <host:port>
Queries
The module supports a query for one validator consensus address and a query for all stored provider records.
FibreProviderInfo
Queries Fibre provider information for a specific validator consensus address.
message QueryFibreProviderInfoRequest {
// validator_consensus_address is the validator consensus address (celestiavalcons...).
string validator_consensus_address = 1;
}
message QueryFibreProviderInfoResponse {
// info contains the fibre provider information.
FibreProviderInfo info = 1;
// found indicates if the validator has registered info.
bool found = 2;
}
HTTP gateway route:
GET /valaddr/v1/fibre-provider-info/{validator_consensus_address}
AllFibreProviders
Queries all stored Fibre provider records. This is not filtered to the active validator set and has no pagination argument.
message QueryAllFibreProvidersRequest {}
message QueryAllFibreProvidersResponse {
// providers contains all fibre providers with a host defined.
repeated FibreProvider providers = 1;
}
message FibreProvider {
// validator_consensus_address is the validator consensus address (celestiavalcons...).
string validator_consensus_address = 1;
// info contains the fibre provider information.
FibreProviderInfo info = 2;
}
HTTP gateway route:
GET /valaddr/v1/all-fibre-providers
Parameters
The x/valaddr module has no parameters.
Genesis
GenesisState is empty. Provider records are not imported from genesis and are not exported into genesis.
message GenesisState {}
Client
CLI Commands
Query commands:
# Query one validator's Fibre provider info by consensus address.
celestia-appd query valaddr provider <validator-consensus-address>
# Query all stored Fibre provider records.
celestia-appd query valaddr providers
Transaction commands:
# Set Fibre provider host. The --from key must correspond to the validator operator account.
celestia-appd tx valaddr set-host <host:port> --from <validator-operator-key>
Encoding
What goes into the original data square?
The Fibre DA scheme does not store Fibre blob payload data in the original data square. Blob payload data is encoded separately into RSEMA1D rows. The original data square only stores metadata that lets readers find and verify the Fibre blob.
There are two Fibre-related entries in the original data square:
-
Accepted SDK transactions containing exactly one
MsgPayForFibreand no other messages are included in their own reserved namespace. ThePAY_FOR_FIBRE_NAMESPACEis0x0000000000000000000000000000000000000000000000000000000005. These transactions are encoded as compact transaction shares using share version 0. -
During data-square construction, the state machine synthesizes one system-level blob for each accepted
MsgPayForFibre. This blob is appended as sparse shares. It uses the namespace from thePaymentPromiseand share version 2.
The share version 2 system blob has the following first-share layout:
- namespace version: 0
- namespace ID: the namespace ID specified in the
PaymentPromise - share version: 2
- sequence start indicator: 1
- sequence length: 36 bytes
- signer: the 20-byte signer address decoded from
MsgPayForFibre.Signer - Fibre blob version: the 4-byte big-endian
PaymentPromise.BlobVersion - Fibre commitment: the 32-byte
PaymentPromise.Commitment - padding: zeros to the end of the 512-byte share
The 36-byte sequence is exactly:
fibre_blob_version_u32be || fibre_commitment_32

What goes into the RSEMA1D rows?
Protocol defaults
The current implementation supports Fibre blob version 0.
Default protocol parameters for version 0:
- original rows: 4096
- parity rows: 12288
- total rows: 16384
- encoding ratio: 0.25
- minimum row size: 64 bytes
- maximum blob size, including the Fibre blob header: 128 MiB
- maximum user payload size: 128 MiB - 5 bytes
The 4096 original-row count pairs with the 64-byte minimum row size to make the smallest paid upload step 4096 * 64 = 256 KiB. The 64-byte minimum comes from the Leopard/GF(2^16) Reed-Solomon layout. Fewer rows would reduce this step size for small blobs, but would increase Merkle proof overhead per byte; very small choices such as 512 or 1024 rows make proof bandwidth large enough that validators may be close to downloading the whole blob anyway.
The 1:3 original-to-parity ratio means any 4096 rows out of 16384 are enough to reconstruct the blob, so the row recovery threshold is 1/4 of the extended data. Fibre uses this instead of a 1:2 ratio, where recovery would require 1/3 of the extended data, because the validator liveness target is already 1/3 of voting power. A 1/4 row threshold gives room for assignment rounding, duplicate rows, slow or missing validators, and bad rows discarded by RLC verification.
The chosen shape also fits the codec cleanly: K = 4096 and K + N = 16384 are both powers of two, and the total row count is well below the GF(2^16) limit of 65536. It also satisfies stricter compatible-library bounds such as K + next_power_of_two(N) = 4096 + 16384 = 20480 <= 65536. A 1/3 encoding ratio with K = 4096 would imply 12288 total rows, which is mathematically plausible but not a power-of-two total for the current RSEMA1D configuration.
Fibre blob v0 byte stream
Fibre blob payload data is not prefixed with a length in every row. Instead, the whole blob has one 5-byte header at the start of row 0:
blob_version_u8 || original_data_size_u32be || original_data
For version 0:
blob_version_u8is always0original_data_size_u32beis the original user payload length, encoded as a 4-byte big-endian unsigned integeroriginal_datais the user payload
The user payload must be non-empty and must not exceed 128 MiB - 5 bytes.
Row size
For a payload of data_len bytes:
total_len = 5 + data_len
row_size = ceil(total_len / 4096), rounded up to the nearest multiple of 64
The upload size paid for by the PaymentPromise is:
upload_size = row_size * 4096
Original row assembly
The original rows are assembled as follows:
- row 0 reserves the first 5 bytes for the Fibre blob header
- row 0 payload bytes begin immediately after the header
- full middle rows contain payload bytes directly, with no row-local metadata
- if the final payload row is partial, it is zero-padded to
row_size - any remaining original rows are all-zero rows
Padding zeros are distinguished from significant payload zeros by the original_data_size_u32be field in the blob header, not by per-row length prefixes.
Parity rows and commitment
The RSEMA1D encoder receives 4096 + 12288 rows. Original rows occupy rows[0:4096]; parity rows occupy rows[4096:16384].
Encoding fills the parity rows, builds a Merkle tree over all extended rows, derives random linear combination coefficients from the row Merkle root, computes RLC values for the 4096 original rows, and builds a Merkle tree over those RLC values.
The Fibre commitment is:
SHA256(row_root || rlc_root)
Decoding
Decoding reconstructs enough rows to recover the original row region, parses the 5-byte v0 header at the start of row 0, verifies that the blob version is 0, checks that the original data size is non-zero and within the configured maximum, and returns exactly:
bytes[5 : 5 + original_data_size]
REST API Reference
The auto-generated REST API reference is available at swagger/.
It covers gRPC-gateway endpoints for Celestia custom modules and Cosmos SDK modules.